Can Coding Agents Program in M&Ms Language?
What happens when you challenge a coding agent with an esoteric programming language it has never seen (freshly invented, with very few examples), and where the source code is literally colored M&Ms on a table? No documentation beyond the opcode table. No Stack Overflow threads. No training examples to memorize. Just six candy colors, a stack machine, and a dare.
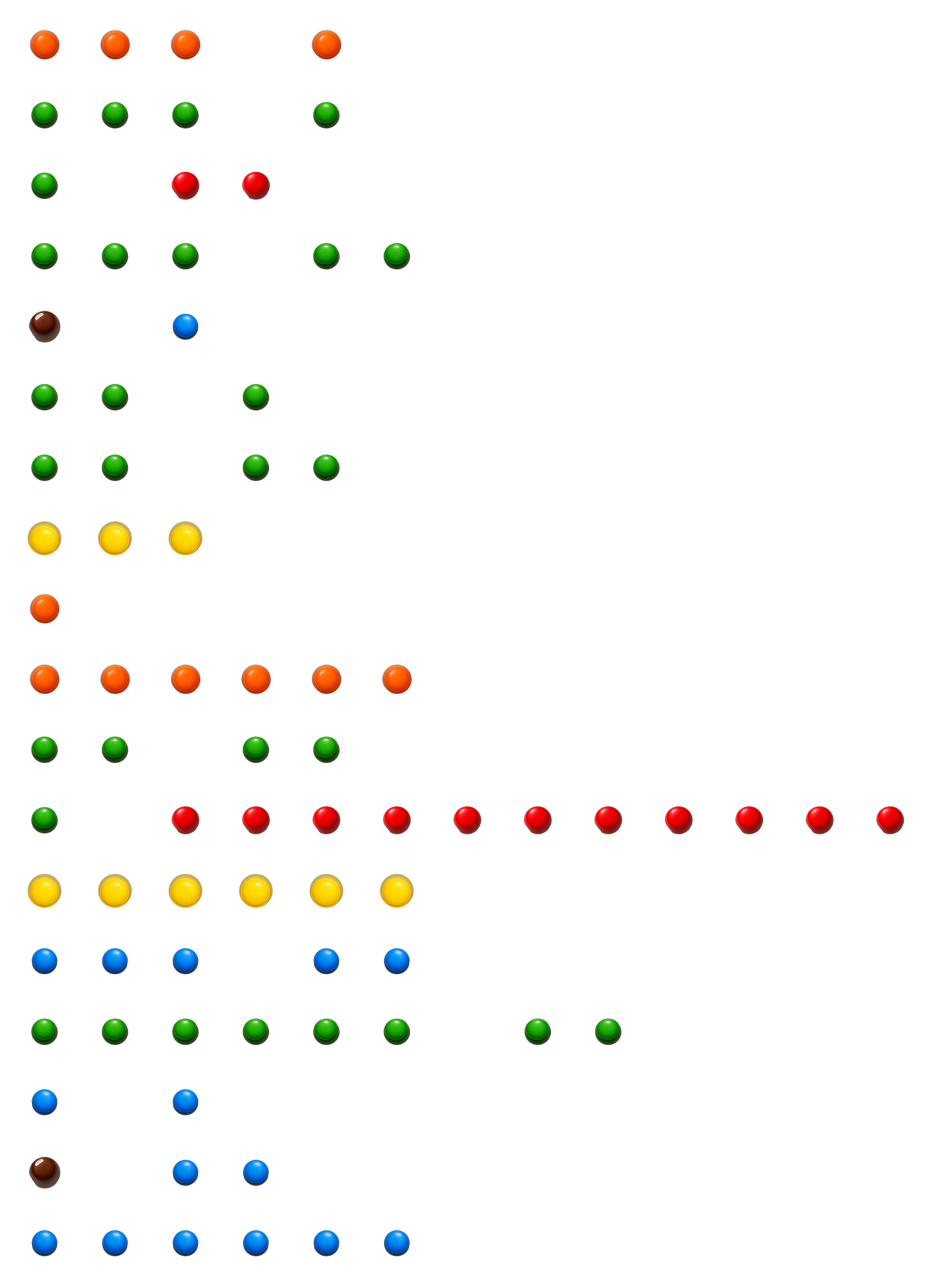 I tried it with MNM Lang, a toy language amazingly created by Mufeed VH where programs are grids of candy-colored tokens (
I tried it with MNM Lang, a toy language amazingly created by Mufeed VH where programs are grids of candy-colored tokens (Blue, Green, Red, Yellow, Orange, browN). Token length encodes operand values. Strings and inputs live in a sidecar JSON file. The whole thing compiles to a PNG of M&M sprites. So funny by design, for humans. But could an LLM learn to write it?
Again: no training examples, no worked solutions, no hints. Just the README spec and the opcode table. Could an LLM figure out the semantics and produce correct MNM Lang programs?
I gave Claude Code (Claude Opus 4.6) 26 challenges of increasing difficulty, from “sum 1 to N” to “write a Brainfuck interpreter”. No hand-holding, no worked examples beyond the opcode table in the README. The agent had to figure out the language semantics from the spec and produce working programs.
The result: all 26 challenges solved. Including a 1,260-line Brainfuck interpreter.
What MNM Lang Looks Like
Each row is one instruction. The opcode is determined by the color and length of the first token. Operands follow. GGG GG means STORE (3 greens) into variable slot 1 (2 greens, value = length - 1 = 1). That’s the entire encoding: count the candies.
The Challenges
I designed 26 challenges across five difficulty tiers:
Easy (1-10): Sum 1..N, countdown, even/odd, max of two, absolute value, multiplication table, power of two, multiply by addition, integer average, sum of digits.
Easy/Medium (11-20): M&M total counter, most common color, vending machine change, staircase pattern, string length, repeat phrase, palindrome number, Collatz sequence, run-length decoding, mini gradebook (min/max/average).
Hard (21-22): Recursive Fibonacci using CALL/RET, a tiny VM interpreter (meta-interpretation: a VM inside a VM).
Bonus (23-25): M&M histogram, digital clock with carry, Caesar cipher.
Epic (26): A full Brainfuck interpreter.
The agent tackled them in order. Each challenge required reading the spec, understanding the stack semantics (pop order matters!), and producing both a .mnm source file and a .mnm.json sidecar with the right variable layout and input queues.
What Went Wrong (At First)
It wasn’t a clean sweep on the first try. Off-by-one in token encoding (35 R’s instead of 36 for ASCII 35), inverted branch polarity in the palindrome checker, variable slot collisions causing infinite loops, wrong comparison operators exiting one iteration too late. The kind of bugs you’d expect from anyone learning an unfamiliar stack machine with no type checker and no linter.
But the agent self-corrected every time: I pointed out the wrong output, and it re-read the spec, found the bug, and fixed it. The debugging cycle was exactly what a human would do with an unfamiliar language, just faster.
The Brainfuck Interpreter
Challenge 26 is where things got wild. The task: implement a complete Brainfuck interpreter in MNM Lang. All 8 BF operations (> < + - . , [ ]), including nested bracket matching with depth tracking.
The fundamental problem: MNM Lang has no arrays and no indirect addressing. You can LOAD var[3] but you can’t LOAD var[x] where x is computed at runtime. For a BF interpreter, you need random access to both the program (to fetch the current instruction) and the tape (to read/write the current cell).
The solution: comparison chain dispatch. To fetch program[IP], the interpreter does:
# Is IP == 0? Load var[10], return.
# Is IP == 1? Load var[11], return.
# Is IP == 2? Load var[12], return.
# ... (120 cases)
Three subroutines (fetch, tape_load, tape_store), each a linear scan over all possible indices. The fetch subroutine alone is 120 cases. The tape subroutines are 20 each. The whole program is 1,260 lines of MNM source, using 174 labels. It was generated by a Python script (generate.py) that the agent also wrote.
And it works. Here’s what it looks like as candy:
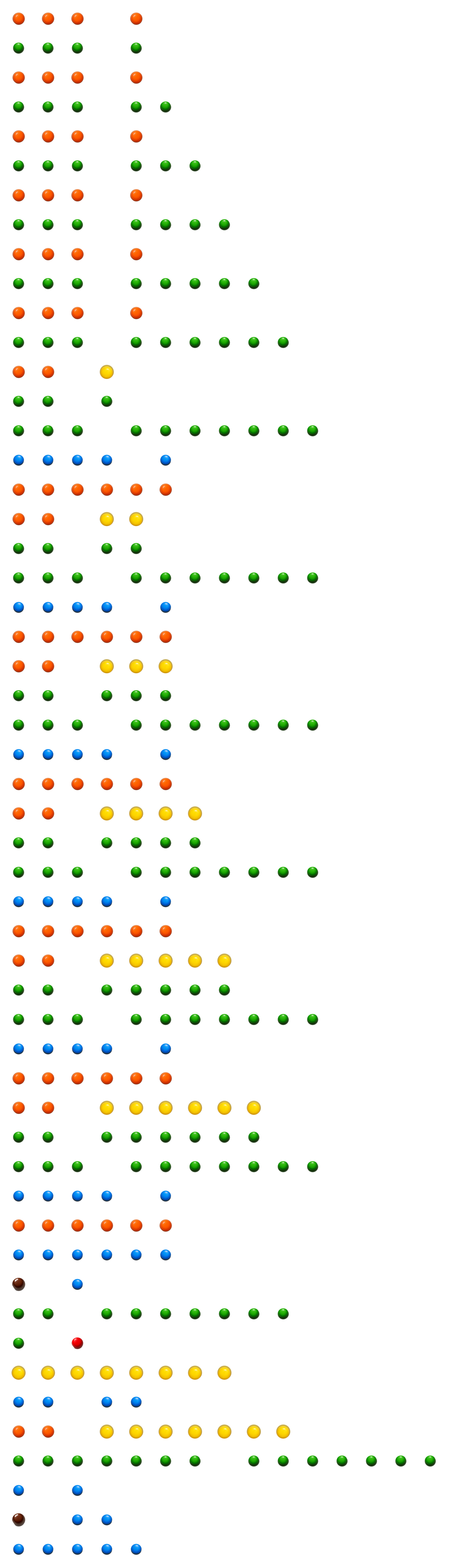
The M&M histogram challenge (53 lines), which prints horizontal bar charts of candy counts. The Brainfuck interpreter is 1,260 lines of this.
Cross-Validation
To verify the Brainfuck interpreter actually works, I co-developed with the agent a cross-validation test suite (tests/test_brainfuck.py). I pushed it toward this testing style: every BF program runs through both a reference Python BF interpreter and the MNM BF interpreter, and we assert identical output. Writing correct Brainfuck programs is itself non-trivial (especially with unbounded integers instead of wrapping cells), so several BF test programs needed debugging too. 39 test cases across multiple categories:
| Category | Programs | Examples |
|---|---|---|
| Basic | 5 | Empty, single dot, increment, decrement |
| Movement | 3 | Multi-cell read/write, bounce |
| Loops | 6 | Simple multiply, clear, skip, nested, countdown |
| Input | 3 | Echo, add, reverse |
| Edge cases | 3 | No output, adjacent loops, add two inputs |
| Real-world | 15 | Hello World, multiply, power-of-2, sum-of-N, Fibonacci |
| Tape state | 4 | Verify final memory layout |
The Hello World BF program runs through the MNM interpreter in ~1.4 seconds and 1.6 million steps. It produces the correct 13 ASCII values: 72 101 108 108 111 32 87 111 114 108 100 33 10 (Hello World! plus newline).
The Fibonacci BF program, itself running inside the MNM BF interpreter, correctly outputs [1, 1, 2, 3, 5, 8, 13] for N=7. That’s a Fibonacci computation running inside a Brainfuck program running inside an MNM Lang interpreter. Three levels of interpretation.
What This Tells Us
MNM Lang is a good test for coding agents for a few reasons:
Unfamiliar territory. There are essentially zero MNM Lang programs in any training corpus. The agent can’t pattern-match against memorized solutions. It has to actually reason about the language specification.
Hostile encoding. The token-length-as-value scheme means you can’t eyeball correctness. Is GGGGGGG a DEC instruction or a 6-green operand? Context matters, and off-by-one errors are invisible until runtime.
No safety net. No type checker, no linter, no error messages beyond “wrong output” or “step limit exceeded”. Debugging requires mentally tracing a stack machine, which the agent did successfully.
Scaling test. The jump from challenge 1 (10 lines) to challenge 26 (1,260 lines) is two orders of magnitude. The agent needed to invent architectural patterns (comparison chain dispatch, generated subroutines) that aren’t in any MNM Lang tutorial because there are no MNM Lang tutorials. And the approach of generating MNM programs via a Python script was a practical engineering decision the agent made on its own.
This is similar in spirit to what I observed with Printf-Oriented Programming and a chess engine written in LaTeX. Coding agents can master unfamiliar paradigms, even absurd ones like encoding game logic inside \expandafter chains or printf format strings. But the really interesting question is how far they can scale. With POP, the agents hit a wall at chess-level complexity. With LaTeX, the agent produced a playable chess engine but needed extensive macro plumbing that pushed TeX to its limits. With MNM Lang, the agent pushed through to a working Brainfuck interpreter, but needed a code generator to manage the complexity. The pattern is consistent: agents handle novel paradigms well at small scale, and find creative workarounds (compilers, generators, meta-programming) when direct coding becomes intractable.
Try It Yourself
The fork with all 26 challenges is at github.com/acherm/mnmlang. Each challenge has a .mnm source and sidecar JSON. Run any of them with:
uv run mnm run challenges/01_sum_1_to_n/sum.mnm
uv run mnm run challenges/26_brainfuck/bf.mnm
The cross-validation test suite:
uv run --extra dev pytest tests/test_brainfuck.py -v
@misc{acher2026mnmlang,
author = {Mathieu Acher},
title = {Can Coding Agents Program in M&Ms Language?},
year = {2026},
month = {mar},
howpublished = {\url{https://blog.mathieuacher.com/CodingAgentsMnMLang/}},
note = {\url{https://blog.mathieuacher.com/CodingAgentsMnMLang/}}
}
LLM coding agents esoteric languages MNM Lang Brainfuck generative AI llm4code Claude Code