Debunking the Chessboard: Confronting GPTs Against Chess Engines to Estimate Elo Ratings and Assess Legal Move Abilities
Can GPTs like ChatGPT-4 play legal moves and finish chess games? What is the actual Elo rating of GPTs? There have been some hypes, (subjective) assessment, and buzz lately from “GPT is capable of beating 99% of players?” to “GPT plays lots of illegal moves” to “here is a magic prompt with Magnus Carlsen in the headers”. There are more or less solid anecdotes here and there, with counter-examples showing impressive failures or magnified stories on how GPTs can play chess well. I’ve resisted for a long time, but I’ve decided to do it seriously! I have synthesized hundreds of games with different variants of GPT, different prompt strategies, against different chess engines (with various skills). This post is here to document the variability space of experiments I have explored so far… and the underlying insights and results.
 The tldr; is that
The tldr; is that gpt-3.5-turbo-instruct operates around 1750 Elo and is capable of playing end-to-end legal moves, even with black pieces or when the game starts with strange openings.
However, though there are “avoidable” errors, the issue of generating illegal moves is still present in 16% of the games. Furthermore, ChatGPT-3.5-turbo and more surprisingly ChatGPT-4, however, are much more brittle. Hence, we provide first solid evidence that training for chat makes GPT worse on a well-defined problem (chess). Please do not stop to the tldr; and read the entire blog posts: there are subtleties and findings worth discussing!
GPTs and Chess since the 2020 prehistoric days
If you read this blog or follow me on X/Twitter, you know I have been interested in a while about generative AI technologies and chess. For instance, I have reported on GPT-2, one of the first promising version of GPT and trained on 3.5 million chess games with 146 TPUs (ouch!). This specialized version of GPT-2 played well during standard openings due to its training data but quickly blunders thereafter. While it consistently makes legal moves without understanding chess (even 30 moves into a game!), its performance was easily outclassed by traditional chess engines and human players – see some games in the blog post. At that time, it was impressive to see that transformers and a text completion engine can partially learn chess rules from pure text.
Since then, I have publicly shared and discussed some experiments like a prototype to play chess games with GPT-3 https://twitter.com/acherm/status/1616477887607242752 including some analysis that basically shows that GPT-3 proposes lots of illegal moves. I have also shown some failures of ChatGPT-4 https://twitter.com/acherm/status/1636441376375095306 Even this summer ChatGPT-4 has been defeated by Chessman Elite (beginner level, instantaneous answer, coming from the 90s): https://twitter.com/acherm/status/1691123390298443780
Obviously, I’m not alone to share chess-related stuff about GPTs, there are many examples here and there: eg https://twitter.com/GothamChess/status/1624755982105513992 https://www.youtube.com/watch?v=svlIYFpsWs0 In general, I like the interactions and discussions we can have on this subject, with interesting recommendations and food for thoughts. I also much appreciate the interventions of Gary Marcus that heroically tries to ponder some crazy over-claims of GPT aficionados!
Overall, I have compiled a long list of chess+GPT things to explore and, well, I’ve resisted for a long time. But I’ve decided to do it more seriously!
Signals and related work in the X/Twitter space
The basic reason is that Grant Slatton reported, on a quite viral tweet https://twitter.com/GrantSlatton/status/1703913578036904431, that “the new GPT model, gpt-3.5-turbo-instruct, can play chess around 1800 Elo.” Interestingly, Grant had previously reported that ChatGPT-4 https://twitter.com/GrantSlatton/status/1699441158450270472 cannot really play chess, on par with my past observations and informal experiments. Following Grant’s tweet, Joel Eriksson also suggested that “GPT-3.5 playing chess against Stockfish set to 1700 ELO.” https://twitter.com/OwariDa/status/1704170914659582281 and shared some code. Though I disagree with the claim and the follow-up tweet (“Ping @ylecun, @GaryMarcus & others who claim LLMs are incapable of reasoning, and don’t create world models”), I find the results intriguing and toke it as a reproducibility challenge ;-) Also, Boris Power member of technical staff at OpenAI stated “I don’t think anything has been published, unfortunately. ELO is around 1800” https://twitter.com/BorisMPower/status/1690050553525792768
Another signal that caught my attention was an experiment suggesting that if you throw the first random moves, GPTs fall apart: https://twitter.com/GaryMarcus/status/1706672864970363106. (Remarkably, the tweet has been deleted since then, with nice clarifications: https://twitter.com/paul_cal/status/1707303586932072862)
An issue of all these signals in the X/Twitter space is that people very quickly jump to strong conclusions or interpretation or excuses. There are also interesting hypotheses like “it appears this was just the RLHF’d chat models. The pure completion model succeeds.” to explain the sudden improvement https://twitter.com/GrantSlatton/status/1703913578036904431. Overall, all of these calls to investigate seriously some interesting questions, in short to reproduce and replicate experiments!
Questions and method
A first natural question is to assess the Elo rating of GPTs. Beforehand and hence a pre-requisite question is to assess the ability of GPTs to play legal moves. After all, playing illegal moves in practical chess settings has the consequence of losing games and decreasing your Elo rating!
A general issue with all these experiments I’ve read on X/Twitter, including mine, is that we’re not sure about the generalization of results. Most of the experiments have been done on specific GPTs, with specific prompts, against specific engines, with only a few games. For instance, “Reports of illegal moves are pretty common so I find this hard to swallow, Wondering about your methods and sample size.” https://twitter.com/GaryMarcus/status/1704112674932502767
Hence, there is an opportunity to automate the experiments (e.g., for synthesizing games of GPTs) and then expand the set of experiments.
Variability space of experiments
In order to assess ability of playing legal moves and Elo rating, one essentially needs to play GPTs against different opponents. Many^many experiments are possible. If we think deep and consider every detail, there are numerous variation points together with possible alternatives and values. I’m detailing them hereafter.
GPT model: gpt-3.5-turbo-instruct, text-davinci-003, gpt-4, gpt-3.5-turbo
I only considered OpenAI GPT models. “Open source” models, such as LLaMa2, Falcon, or Mistral can be used as well, but I have doubts they’ve been trained on chess games.
I have selected:
gpt-3.5-turbo-instructsince this model has caught recent attention. This model can be used through the OpenAI API. Interestingly, this model only serves for text completion and has not been tuned for “chat”.text-davinci-003an early model for text completion, also available through OpenAI API.gpt-4: as the name does not suggest, this model is used for chat purposes, for interacting through different messages. Hence, it should be understood as “ChatGPT-4”, the model used as part of ChatGPT Plus.gpt-3.5-turbo: this model is also used for chat purposes and should be understood as “ChatGPT-3.5-turbo” (i.e., an alternative to “ChatGPT-4”)
Temperature: 0, 0.8
All these GPT models come with hyperparameters. I have considered:
- temperature: between 0 and 1 (or 2 in chat mode)… https://platform.openai.com/docs/api-reference/completions “Lower values for temperature result in more consistent outputs, while higher values generate more diverse and creative results.” I have mainly considered 0 to have consistent results and prior experiments rely on 0 value as well. More creativity (and higher temperature) can intuitively lead to either verbose answers or to textual moves that have more chances to be illegal. For the record, I’ve tried
gpt-3.5-turbo-instructwith temperature 0.8 as well. - max_tokens: 5 or 6. Same value as for prior experiments. A move in PGN notation is usually 3 characters (
Nf6), but there can be moves likeexd8=Q. So 5 or 6 value seems reasonable. In chat mode, we also want to avoid explanations; we only want parsable moves!
Taking a step back, the setting of temperature value (or max_tokens) is something impossible in the ChatGPT Web interface: you have to go through the APIs to be able to control. Hence, a retrospective hypothesis is that prior experiments used ChatGPT-3.5 or ChatGPT-4 with unknown, uncontrolled temperatures and max_tokens, both can influence the quality of the answers. In our personal research on code synthesis, we have shown that temperature can have a large influence on the quality of the generated code by Codex and Copilot. It’s the advantage of carefully doing experiments and automating: one can at least control some variability of the experiments!
Prompts: basic, altered, chat-oriented
Prompts aka the instructions you’re giving to GPTs obviously matter. I use the following prompt for gpt-3.5-turbo-instruct
[Event "FIDE World Championship Match 2024"]
[Site "Los Angeles, USA"]
[Date "2024.12.01"]
[Round "5"]
[White "Carlsen, Magnus"]
[Black "Nepomniachtchi, Ian"]
[Result "1-0"]
[WhiteElo "2885"]
[WhiteTitle "GM"]
[WhiteFideId "1503014"]
[BlackElo "2812"]
[BlackTitle "GM"]
[BlackFideId "4168119"]
[TimeControl "40/7200:20/3600:900+30"]
[UTCDate "2024.11.27"]
[UTCTime "09:01:25"]
[Variant "Standard"]
1.
with the idea of concatenating played moves and transmits the game in PGN format: GPTs have to complete the rest. Prompt engineering is clearly a thing, and a bit of mystery. There have been some discussions about the effectiveness of this specific prompt (like the presence of Carlsen as a white player in the headers would force GPTs to play well). Why not. I have tried an altered prompt:
[Event "Chess tournament"]
[Site "Rennes FRA"]
[Date "2023.12.09"]
[Round "7"]
[White "MVL, Magnus"]
[Black "Ivanchuk, Ian"]
[Result "1-0"]
[WhiteElo "2737"]
[BlackElo "2612"]
1.
to explore a bit the effect of PGN headers. Also, as a side note, I have early tried other prompts, more directive (“You play a chess game…”), and there were less effective. What seems effective with the original prompt is that the text completion of gpt-3.5-turbo-instruct is well-suited. It puts a “PGN context” and calls the attention into completing the moves in chess game notation.
Prompting in chat mode
The story is different with “chat” GPTs like gpt-4 and gpt-3.5-turbo. These models have been fine-tuned for chatting and also the exposed API differs https://platform.openai.com/docs/guides/gpt/chat-completions-api. Early experiments with the original or the altered prompt lead to the following situation: gpt-4 and gpt-3.5-turbo tend to be verbose and in “explanations” mode, eventually not playing moves or playing dubious, non parseable moves!
Hence, an idea is to leverage API facilities and set a “role” (see below) while providing a series of messages that are moves played alternatively by the chess engine or the GPT. Basically something like:
[{'role': 'system', 'content': "You are a professional, top international grand-master chess player. We are playing a serious chess game, using PGN notation. When it's your turn, you have to play your move using PGN notation."}, {'role': 'user', 'content': '1. d4'}, {'role': 'user', 'content': '1... d5'}, {'role': 'user', 'content': '2. Qd3'}, {'role': 'user', 'content': '2... Nf6'}, {'role': 'user', 'content': '3. Nf3'}]
This strategy proved to be effective and can be automated, though evils are in the details (more details hereafter). Something I did not explore much is to vary the “role” content.
It should be noted that this strategy differs from the original prompt of GPT models for text completion. Engineering “prompts” (and interactions) is definitely important!
White or black pieces: true or false
Something that has been surprisingly not considered so far is the ability to play with black pieces. Playing with white pieces is in theory (or in the practical world of chess human players) an advantage, and it’s good to balance with games with black pieces. Also, starting with black pieces brings some diversity.
Opponents and chess engines: random, SF with skill levels
GPTs can play chess, but against who?
I considered two variants:
- a random chess engine: An automated procedure that picks a random move across all possible legal moves in a given chess position. On the one hand, this engine is very weak from a chess level perspective: I don’t know what is the Elo rating but it would be very low. On the other hand, a random engine plays very strange moves that may cause issues for GPTs, since not in the usual training set.
- the Stockfish chess engine at different “skills” and in different settings (see details below)
Stockfishes
Stockfish (SF) is a state-of-the-art, open source chess engine. SF with full power, even on a basic computer, is unbeatable even for top grand-masters and the estimated Elo is more than 3500 (Magnus Carlsen is still dreaming of reaching the incredible 2900). Hence, an idea is to weaken SF rather than to optimize it https://github.com/official-stockfish/Stockfish/wiki/Stockfish-FAQ#optimal-settings
There are lots of parameters of SF that can be controlled, both having an effect on the Elo rating.
I have played a bit with depth, Elo rating, and Skill level. The conclusion is that it’s easy to perform mistakes (e.g., setting Elo rating, keeping the depth to 15, and letting only 1 second to play), since it’s highly sensitive to your hardware and workload. Hence, a better strategy is to use Skill level and rely on Elo estimates here: https://github.com/official-stockfish/Stockfish/issues/3635#issuecomment-1159552166
By the way, super interesting discussion in this issue! What I’ve learned is that the estimates have to be taken with caution, since the numbers have been calibrated for a specific version of SF. I have also used depth=20 (instead of 15). (By the way, an immediate threat to my experiments is the SF version: I’ve exclusively used ` ./stockfish/stockfish/stockfish-ubuntu-x86-64-avx2
Stockfish 16`. In general, there are other factors that can influence the result: hardware, SF settings such as Hash, Threads, etc.). Yet, it is the best method so far I know of.
I have tried different values of Skill level, from estimates of 1300 Elo to 2000 Elo, to make vary the strength of opponents.
Diversity of openings: uncontrolled, predetermined
A threat I was anticipating is the lack of diversity for the first moves (eg always the same opening and series of moves), either due to SF or GPTs. Hence, I have started programming ways to diversity with known, predetermined openings, e.g.:
###### case known first moves (to diversify a bit the openings)
def diversify_with_knownopenings():
nmove = 2
base_pgns = [
'1. e4 e5 2.',
'1. d4 Nf6 2.',
'1. e4 c5 2.',
'1. d4 d5 2.',
'1. e4 e6 2.']
However, SF has in fact some “randomness” in the search procedure, even for the first moves. Overall, games tend to be diverse enough and not to be the repetition of already played games. Hence, there is no need to control first moves for reaching diversity.
Random first moves: n=10 or n=20
Yet another variation point of the experiment is to start the game with random first moves. Let say, for instance, the n=10 first moves. And then, and only then, letting GPTs and SF play.
The idea is that the n=10 random moves make the games strange and out of distribution of what GPTs have learned. Hence, the text completion can fail and produce illegal moves. An experiment suggested it https://twitter.com/GaryMarcus/status/1706672864970363106
Here, we have to find (counter-)examples of failing cases.
Sampling the variability space
If we consider all possible “values” of:
- GPT-model
- temperature
- max_token
- prompt
- white or black pieces
- engines with skill levels
- random first moves or not
and combine all possible values, the number of experiments is huge. Let say: 4 possible values for GPT-model, 5 values for temperature, 3 values for max_token (I’m oversimplifying!), 2 values for prompt, 2 values for white/black pieces, 4 values for engines, and 3 values for random first moves or not… It’s already 2880 experiments and only one game per experiment!
Unfortunately, playing only one game per experiment would be a huge threat for measuring ability to play legal moves or for assessing Elo rating. Both GPTs and SFs have randomness and are stochastic, while considering a limited variability of chess game (only 1 among billions^billions possible) would not be representative at all. The point is we also need to repeat experiments and play several games to draw solid conclusions. 10 games, 2880 experiments and settings: 28800 games. Why not. And not sure 10 is good enough.
If it was a just a question of computing cost, perhaps it’s affordable – one can envision to parallelize the experiments. However, there is another detail: \(\)$$$. You have to subscribe and pay when using the OpenAI API, typically a relatively small amount of dollars per request and tokens. However, thousands of games quickly cost a lot. In particular, gpt-4 (chat mode) costs a lot since the price per token is higher comparatively and also the fact of concatenating moves, in long games, makes a “chat” session not cheap at all.
Hence, there is no escape: I can hardly, as an individual, run all possible experiments and cover the whole variability space. A sample of the experiments is rather needed.
I used various strategies to reduce the variability dimensions:
- I have limited the usage of some GPT models (eg
text-davinci-003) since it was mainly to confirm some counter-examples (eg there is limited hope to improve the situation with higher temperatures) - I have partly explored the temperature for some GPT models and max_tokens was closed to 5 or 6.
- for the experiments with random first moves, I was seeking counter-examples that GPT models would fail. Some other experiments already showed some weaknesses, no need to go further.
I limited the budget to 100$.
Dataset
I’ve compiled 878 games using a combination of GPT models, configurations of chess engines and other variation points previously described:
-
gpt-3.5-turbo-instruct : 573 games, among 401 with white piece and 172 with black pieces
-
gpt-4 : 179 games, among 116 with white piece and 63 with black pieces
-
gpt-3.5-turbo : 53 games, among 53 with white piece and 0 with black pieces
-
text-davinci-003 : 73 games, among 43 with white piece and 30 with black pieces
Analysis and insights
Enough experimental settings and discussions, we want results!
text-davinci-003
Let’s start with text-davinci-003, a relatively old model that serves for text completion.
Out of 73 games with davinci (with white pieces: 43, with black pieces: 30), 72 games contain illegal moves. There are 21 games against random chess engine among the 72 and so they also contains illegal moves. The only game with no illegal move is a defeat against Stockfish (Skill level 3) in 16 moves.
Games were short. The longest game was only 20 moves. The shortest game was 5 moves. The average and median game length was 12 moves. (Terminology note: move is one ply white piece and one ply black piece). In general, actual chess games are more around 40 moves on average.
A qualitative analysis of illegal moves shows that the moves are syntactically correct, but simply impossible on the chessboard (typically, some pieces cannot move to the indicated square).
I did not insist much with text-davinci-003. Altered prompt had no specific effect and the overall conclusion is that text-davinci-003 is unable to play an entire game because of illegal moves quickly generated, against basic SF engine or random chess engine. It is not a big surprise and seems on par with what has been reported: a weak baseline, certainly closed to the specialized GPT-2
gpt-3.5-turbo-instruct
With the model gpt-3.5-turbo-instruct (recall: text completion) I compiled 573 games, among 401 with white pieces and 172 with black pieces.
The 573 games include:
- 439 games:
gpt-3.5-turbo-instructagainst SF - 61 games:
gpt-3.5-turbo-instructagainst random chess engine - 73 games:
gpt-3.5-turbo-instructagainst SF with first random moves to open the game.
It’s the model that caught attention lately, and it deserves to gather more games and experiments (e.g., than text-davinci-003).
Let’s first focus on “normal” games played against SF at various skills.
Move ability against SF
Out of 439 games against SF, 369 were legal games and 70 were illegal games, hence 16% of illegal games. It seems huge at first glance.
We can categorize the illegal moves as follows:
| illegal_move | |
|---|---|
| 1-0 | 49 |
| 1- | 4 |
| Kb3 | 1 |
| gxh8= | 1 |
| Nxa3 | 1 |
| {M. | 1 |
| {[%clk | 1 |
| bxc3 | 1 |
| axb8= | 1 |
| {(Leko-G | 1 |
| dxe8= | 1 |
| cxb8= | 1 |
| bxc8= | 1 |
| Qa7 | 1 |
| f7 | 1 |
| {This | 1 |
| Rxh5 | 1 |
| exf8= | 1 |
| {The | 1 |
By far the most frequent pattern is “1-0” or “1-“: it’s clearly not a legal move, it means white pieces have won! How to interpret this? A first interpretation is simply the inability of gpt-3.5-turbo-instruct to play a legal move in a middle of a game. As a text, statistical-based completion engine, it’s not that surprising after all to complete the game as such. A second interpretation is that gpt-3.5-turbo-instruct resigns on purpose. It’s totally possible in chess to stop the game (and resign) since you consider that you’re losing and have no chance to save the game. Interestingly, all games but one are with black pieces, going into the direction of this hypothesis. Furthermore, most of the games are either forced check mates or clear superior position. In detail, I’ve used SF to analyze the 48 games with 1-0: 19 games lead to forced mates, 25 games with centipawns greater than 5 (significant advantage!), and only 4 games that are unclear. Stated differently, the judgment of gpt-3.5-turbo-instruct is quite accurate, except in 4 games that should be continued. There is also a third case: 1-0 but with white piece. Like: hey, I’m winning, I dare to give the next moves, so 1-0, no discussion.
You can interpret as you want, the interpretations make sense, and are more or less supportive of gpt-3.5-turbo-instruct. My interpretation is in-between: it’s an accidental error due to the very nature of the statistical-based completion, but the assessment of the position looks very accurate… Basically gpt-3.5-turbo-instruct finds that the best completion is to consider it as winning. A possible workaround is to ask gpt-3.5-turbo-instruct another completion (and move) when encountering 1-0. I didn’t implement this workaround, since it’s a grey zone: Are we here to assess GPT or to assess a corrected GPT? Is it fair to allow GPT to propose another move, when the move is illegal in the first place?
A second pattern is the incorrect promotion. Instead of e.g. gxh8= the correct move is most likely gxh8=Q for promoting a queen (can well be a rook, a bishop, or knight…), but as Q is not specified, it’s an illegal move. There are two possible fixes. First is related to max_tokens: experiments with this model and GPT-4, see hereafter, show that increasing max_tokens was not that helpful. A second approach is to help the GPT model and automatically modify the promotion as a queen, thus rewriting and fixing the syntactical move. It’s again a grey zone: Are we assessing GPTs? Or can we take the liberty to fix outcomes of GPT?
A third pattern is related to a kind of unfinished comment: { is the starting of a PGN comment. Yea, it’s really a text completion!
A fourth pattern concerns incorrect moves (no 1-0, no 1-, no incorrect promotion, or starting comment). I’ve manually analyzed the 8 mistakes:
- 3 cases where a piece is “pinned”, that is, a piece cannot be moved, since otherwise the king is checked (e.g. Nxa3 is not possible here: https://lichess.org/foSmbmil#28 or another example here: https://lichess.org/iuVNGc8W#94)
- 3 cases where a piece is jumping another (ie there is an intermediate piece before the targeted square) e.g. https://lichess.org/0GAW3gLY#28 and Qxc6 is not possible
- 1 case where a pawn takes another pawn of the same side (bxc3 is not possible here https://lichess.org/ILffB9ri#26)
- 1 case where the square is not reachable (f7 is not possible: https://lichess.org/O5FD3mc2#348 after 174 games)
The mistakes are illegal moves. I don’t necessarily want to rank illegal moves, but I found the three with pinned pieces a bit tricky. Anyway, rules are rules.
Do temperature and altered prompts influence the ability to play legal moves?
I’ve increased the temperature to 0.8 (instead of 0) for some games. 23.01% of games of the dataset with SF are with temperature 0.8, the rest being temperature 0. Among illegal games, 41 are with temperature=0 and 29 are with temperature=0.8. It’s not a huge difference and significant, but increasing temperature leads to slightly more illegal moves. A qualitative analysis of illegal moves with temperature=0.8 shows that the same patterns are present (1-0, incorrect promotion, etc.).
I’ve also tried to use an altered prompt (see above).
99 games with gpt-3.5-turbo-instruct contains an altered prompt (22.6 % games with altered prompt).
19 illegal games with altered prompts and 51 illegal games with original prompts.
We have, again, similar patterns of illegal moves (“1-0” 16 times, incorrect promotion 1 time, and 2 illegal movements of pieces).
Hence, it seems that temperature and altered prompts have no significant effect on the ability to play legal moves. There is no magic prompt or PGN headers – but the original prompt and idea of putting “in-context” PGN headers is a general good approach.
Black or white pieces?
There are 11 illegal moves with white pieces and 59 illegal moves with black pieces. As previously stated, most of the illegal moves with black pieces are “1-0”, that is, resigning.
Conclusion about ability of gpt-3.5-turbo-instruct to play legal moves
A conclusion is that:
-
On the one hand,
gpt-3.5-turbo-instructis not 100% robust and can generate illegal moves in numerous situations (16% of games!). Though some “easy” fixes/workarounds are possible (by rewriting the generated text or “fairly” re-asking an actual move), there are some invalid moves that remain. If we consider “1-0”, “comments”, and “unspecified promotions” as fixable, then 1.4% of games still contain illegal moves. A possible general strategy is to ask GPT several ordered answers/completions, and choose the next move if the first try is illegal. In any case, some effort is needed to fix GPT and there is no guarantee it will be 100% accurate. -
On the other hand,
gpt-3.5-turbo-instructis capable of playing very long games (up to 174 moves!) with an average game length of 50 moves (median is 44 moves). See box plot below! It’s remarkable since a hypothesis is that GPT has more and more difficulties once a game progress, having more chances to encounter rare positions that are not in the training set. It is not the case, at least for the ability to play legal moves. Another remarkable perspective is to have a look at the frequency of legal moves: “only” 0.3% of moves are illegal (out of 23066 moves played against SF), and “only” 0.091% if we do not consider moves “1-0”.
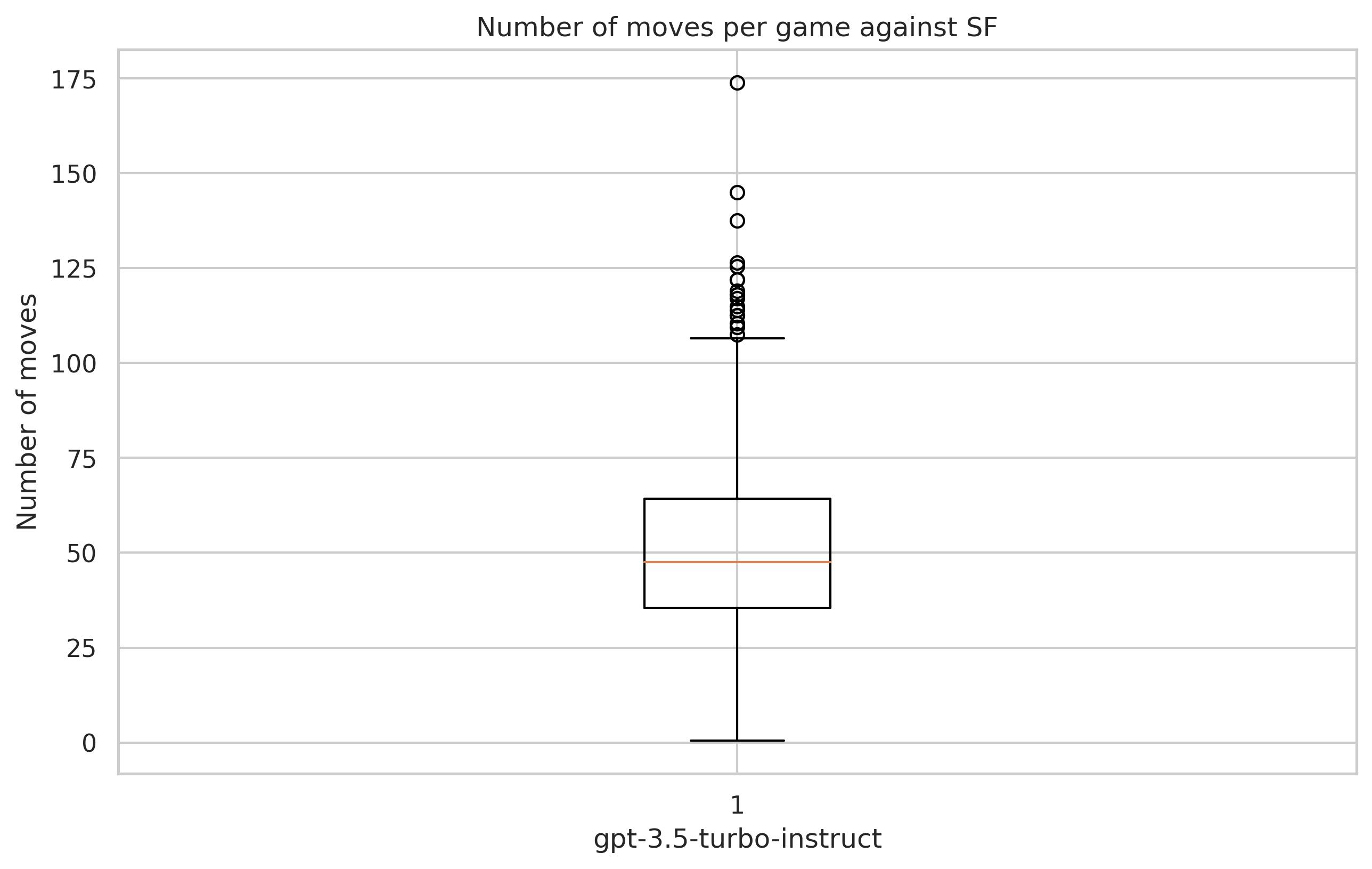
- Obviously, all these numbers should be put in perspective. In a more critical domain, such errors can be dramatic and considered as unacceptable.
Elo rating against SF
Now a more ambitious question: What is the strength and rating of gpt-3.5-turbo-instruct?
A basic estimate is to have a look at the scores against SF. Specifically:
gpt-3.5-turbo-instructscores 142 for games with only legal moves out of 369 games (one win is 1, one draw is 0.5). The score is 38.48%:score = (total_wins + (total_draws * 0.5)) / (total_wins + total_losses + total_draws)- if we count all 439 games (being legal of illegal, considering illegal moves lead to a defeat for GPT)
gpt-3.5-turbo-instructscores 32.35% (142/439).
In addition to the raw score, we have to take the estimated ratings of opponents (SF) into account. In detail, here is the distribution of games against different SF at different skills, together with Elo estimates (see previous explanations).
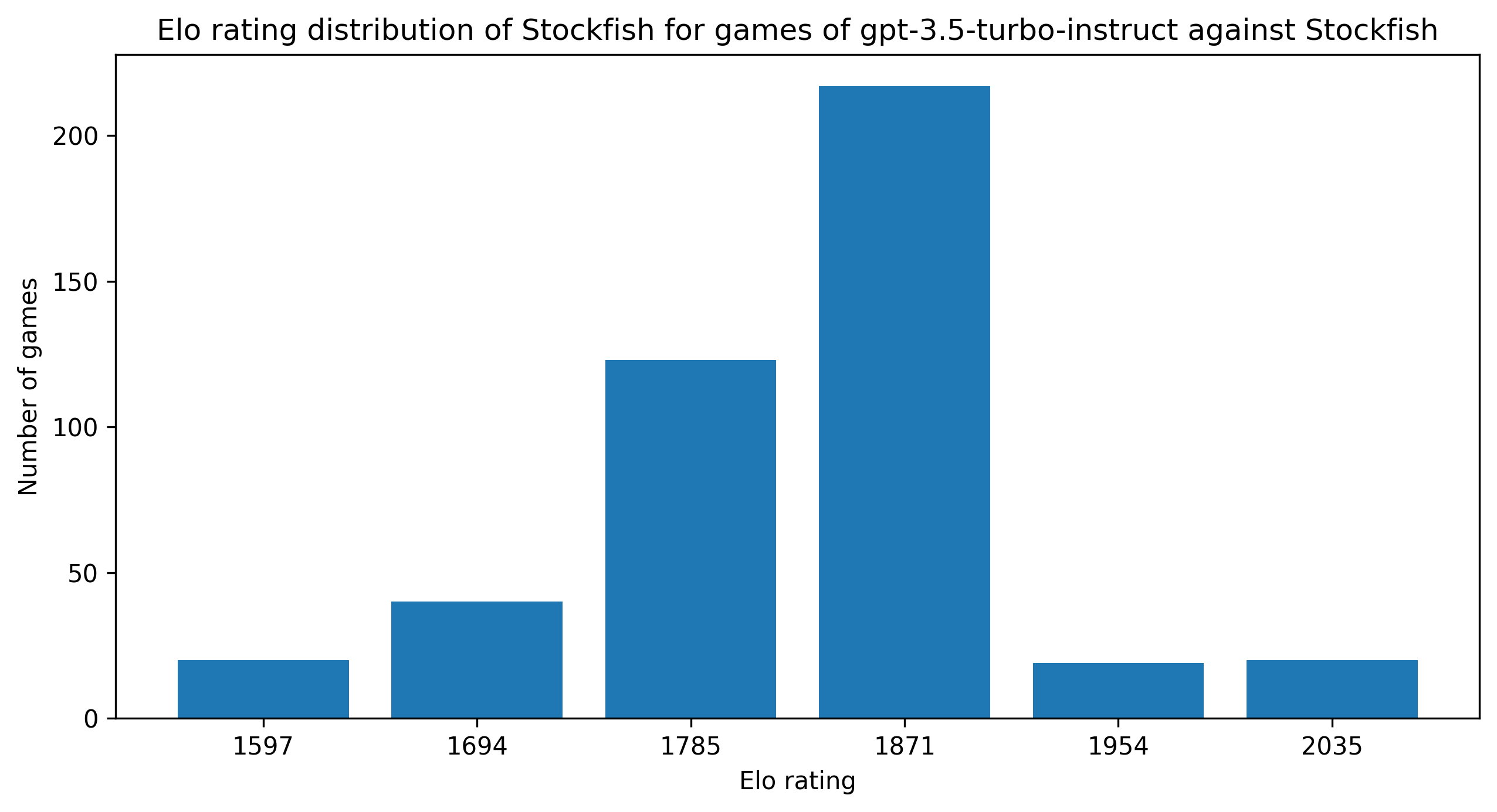
There are several ways to compute the rating of a GPT; it’s part of the variability space of the experiments!
I have retained one method, based on Elo rating system, specifically the method used in the FIDE rating system.
In this system, the performance rating of a player is the average of the ratings of the opponents plus a constant dp.
dp is based on a player’s tournament percentage score p, which is then used as the key in a lookup table available from FIDE Handbook:
def fide_elo_computation(dfe, model_name):
average_opponents_ratings = compute_average(dfe, model_name)
score = compute_score(dfe, model_name)
dp = lookup_fide_table(score)
return average_opponents_ratings + dp
There are debates about how FIDE should compute Elo rating. For example, read the clarification of K. Regan https://rjlipton.wpcomstaging.com/2019/02/03/a-strange-horizon/ in reaction to the report of Jeff Sonas about ratings below 2000, a bit similar to the situation of GPTs.
Anyway, what is the Elo rating of gpt-3.5-turbo-instruct?
- 1743 Elo, considering only legal games
- 1696 Elo considering all games
gpt-3.5-turbo-instruct is capable of winning games against stronger Elo opponents (even more than 2000 Elo!), but it’s not that frequent.
Here is the distribution of scores against SF at different skills.
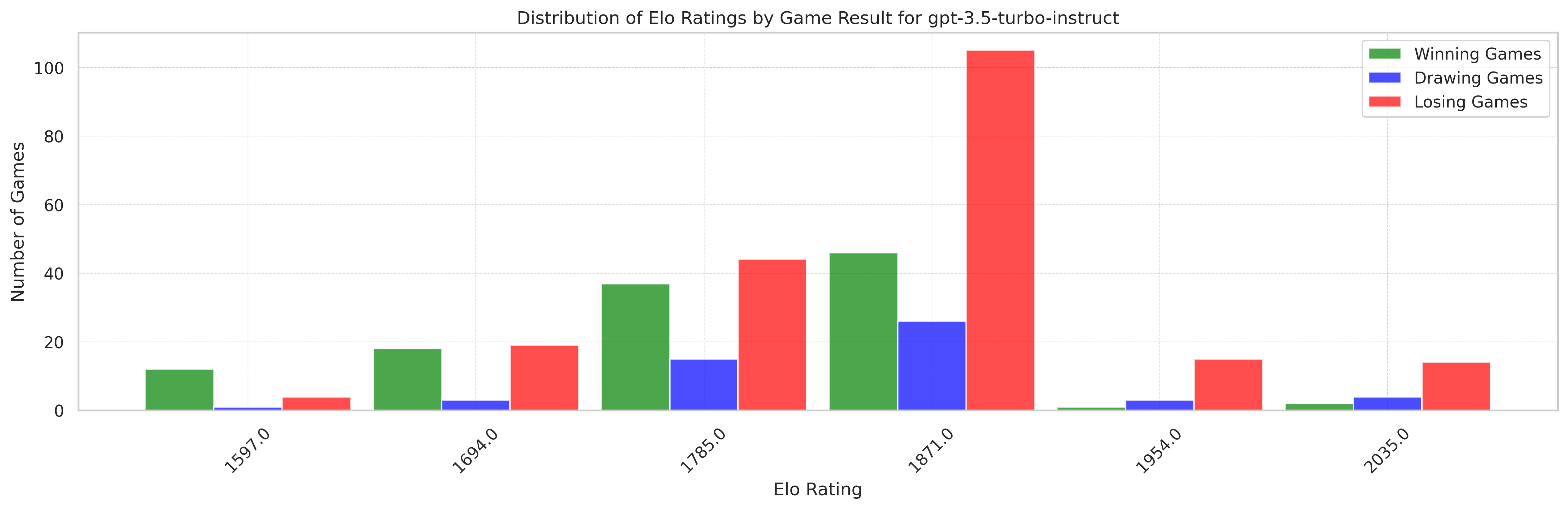
Is gpt-3.5-turbo-instruct better with white pieces against SF?
Good question!
It is tempting to say gpt-3.5-turbo-instruct is (much) better with black pieces, based on following estimates:
- 1725 Elo against SF and only with legal games/moves and only with white pieces
- 1809 Elo against SF and only with legal games/moves and only with black pieces
However, recall that gpt-3.5-turbo-instruct generates more illegal moves with black pieces and resigns when it considers it’s losing.
Hence, here, I would primarily look at all games, even those being illegal. It gives:
- 1715 Elo against SF and with all games and only with white pieces
- 1671 Elo against SF and with all games and only with black pieces
and the trend is reversed!
Do temperature and altered prompts influence Elo?
I’ve increased the temperature to 0.8 (instead of 0) for some games. Previous results apply to either temperature 0 or 0.8. With temperature=0:
- 1789 Elo with only with legal games/moves
- 1742 Elo with all games
With temperature=0.8:
- 1573 Elo with only legal games/moves
- 1519 Elo with all games
Hence, increasing temperature tends to decrease the Elo rating.
I’ve also tried to use an altered prompt (see above). As temperature tends to decrease Elo, I’ve only tried with temperature=0.
The Elo rating with altered prompt is:
- 1808 Elo with only legal games/moves
- 1752 Elo for all games
1752 Elo (resp. 1808 Elo) with altered prompt, temperature=0 is closed to 1742 Elo (resp. 1789 Elo) with original prompt, temperature=0. Hence, it seems that altered prompts have no significant effect on Elo rating (similar to our observations about move generation ability).
We should keep in mind that the dataset is imbalanced (99 games with altered prompts), but there is no reason so far to think that altered prompts would have a significant effect on Elo rating.
Conclusion about Elo rating of gpt-3.5-turbo-instruct
Owing to the different uncertainties regarding Stockfish engines actual Elo rating, the method to compute Elo, the number and diversity of games, and the fact that GPTs generate sometimes illegal moves, it is hard to give a precise and final number. Even providing confidence intervals is not that easy in this context!
A temperature different from 0.0 seems to have a negative effect, and as such it is certainly more fair to consider the Elo rating of gpt-3.5-turbo-instruct with temperature=0.0.
Overall, a reasonable estimate is that the Elo rating of gpt-3.5-turbo-instruct is 1750 Elo (+/- 50 Elo).
It is quite consistent with what have been reported in the informal X/Twitter space: 1700 Elo for Joel Eriksson, 1800 Elo for Grant Slatton and Boris Power.
Robustness and Elo rating of gpt-3.5-turbo-instruct vs random engine
Another set of experiments is related to games against a random chess engine that picks randomly a valid move across possible legal moves. The objective was first to assess ability of gpt-3.5-turbo-instruct to play legal moves, even with a strange opponent.
Out of 61 total games, there were 45 legal games and 16 illegal games. (An illegal game is a game that contains an illegal move due to GPT).
A manual analysis shows that illegal moves can be classified in the “accidental” category:
hxg8= 4
gxh8= 3
{[%clk 2
dxc8= 1
gxf8= 1
exf8= 1
cxd8= 1
{The 1
gxh1= 1
bxc1= 1
A first and main pattern is the incorrect promotion (as previously against SF). A second pattern of illegal moves is a kind of comment or strange textual “artefacts”. Remarkably, the model won 98.89 % of legal games (44 games). The only not won game is a draw: https://lichess.org/bE99x52y is due to repetition.
The legal games were short, mainly due to the poor level of a random chess engine: longest game was 33 moves, the shortest game was 2 moves (fun: 1. g4 e5 2. f4 Qh4# 0-1), the average game length was 14.4 moves, the median game length was 14 moves.
The overall conclusion is that random chess engines are not disturbing much gpt-3.5-turbo-instruct and causing specific difficulty. The illegal moves can somehow been fixed (with a standard, non-AI rewriting procedure) and were already present against SF. If we ignore accidental errors, gpt-3.5-turbo-instruct quickly destroys a random chess engine.
Robustness of gpt-3.5-turbo-instruct with random first moves
The idea here is to start the game with random first moves (leading to a strange opening position) and then there is game between GPT and SF. We used n=10 first moves. We synthesized 73 legal games in this setting. Out of 73, 71 legal games and 2 illegal games. Hence, 3% of illegal games. Illegal moves were: | | illegal_move | |:——|—————:| | Qxc6+ | 1 | | Bc5 | 1 |
Two insights here:
- first, it’s good news that
gpt-3.5-turbo-instructis capable of playing legal moves even with a strange opening position. The results confirm the retraction and quick clarifications: https://twitter.com/paul_cal/status/1707303586932072862. After some discussions and experiments with Paul, the original experiments were not conclusive and reproducible. We are in the X/Twitter space, but some academic works would welcome similar interactions (and possibly retractions) in the open. - second, a qualitative analysis of random first moves shows that games quickly converge to an unfair position, with a clear advantage for white or black pieces. Hence, it doesn’t make any sense to assess the Elo rating in this setting.
gpt-4 (aka ChatGPT-4)
With the model gpt-4 we are dealing with a chat-oriented model, specialized and tuned for sequentially answering to messages (see explanations above).
I compiled 179 games, among 116 with white piece and 63 with black pieces
The 179 games include:
- 85 total games:
gpt-4against random chess engine - 94 total games:
gpt-4against SF - I didn’t gather games with random first moves (future work or not… see results below)
Move ability against SF
Out of 94 games against SF, 64 were legal games and 30 were illegal games, hence 32 % of illegal games. It is huge. We can categorize the illegal moves as follows:
| illegal_move | |
|---|---|
| Bxf6 | 1 |
| Kxf3 | 1 |
| Bxa7 | 1 |
| Kb6 | 1 |
| Nxb6 | 1 |
| Kxb5 | 1 |
| Bg2 | 1 |
| Bb7 | 1 |
| Rd7 | 1 |
| Checkmate! | 1 |
| gxh6 | 1 |
| Rxh1 | 1 |
| Qe5+ | 1 |
| Kxe6 | 1 |
| Kxc4 | 1 |
| Ke4 | 1 |
| Re8+ | 1 |
| Rd1+ | 1 |
| Kxf5 | 1 |
| Kd8 | 1 |
| Qxh3 | 1 |
| Kg3 | 1 |
| Rd3 | 1 |
| Bxf7 | 1 |
| Rxe8 | 1 |
| b5 | 1 |
| Rxa4 | 1 |
| Kxd6 | 1 |
| Kd2 | 1 |
| Kg1. | 1 |
Contrary to gpt-3.5-turbo-instruct, the illegal moves are not “1-0” or “1-“ (resigning) or incorrect promotions but actual moves that are simply not legal.
The trend is with both white and black pieces: 15 illegal moves with white, 15 illegal moves with black.
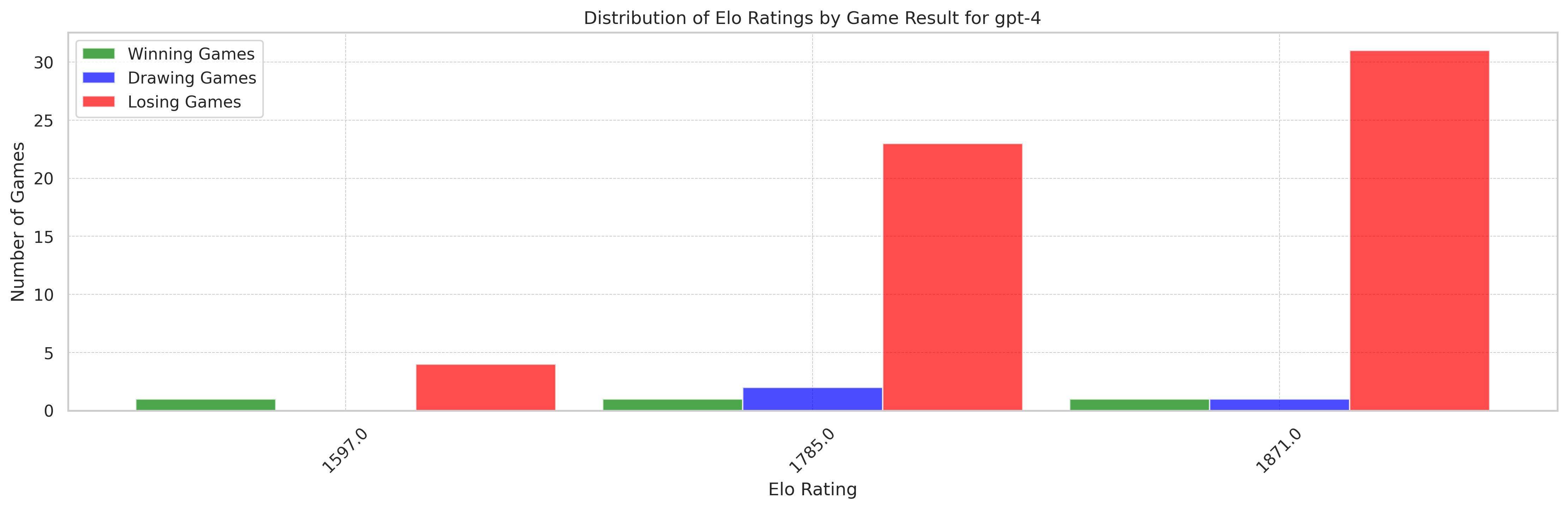
It is remarkable that gpt-4 is capable of playing long games (up to 128 moves!) with an average game length of 48 moves (median is 45 moves). See box plot below!
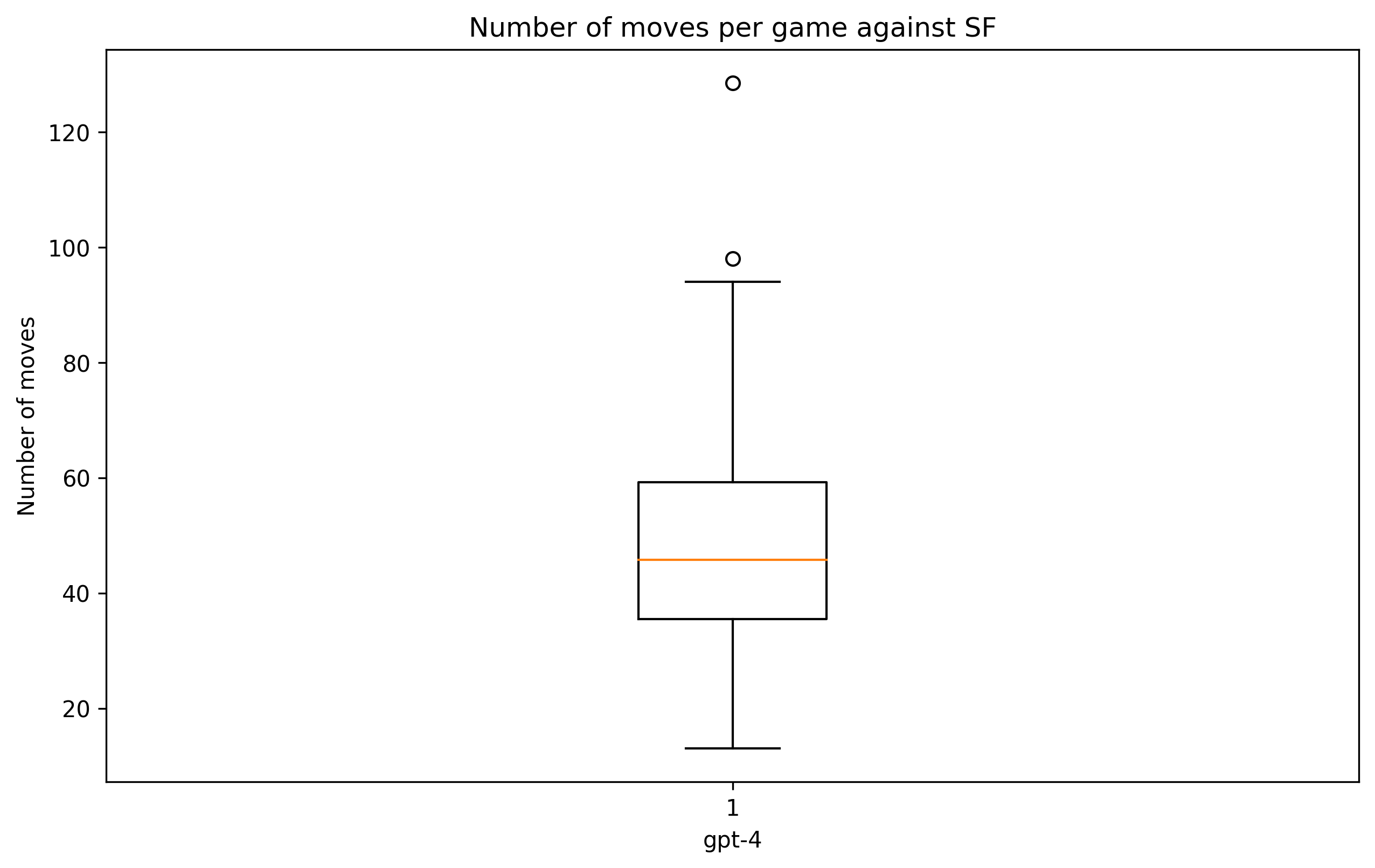
Another perspective is to have a look at the frequency of legal moves: 0.66% of moves are illegal (out of 4527 moves played against SF).
The percentage is much higher than gpt-3.5-turbo-instruct and there is no easy fix: illegal moves are really due to a lack of understanding of the chess rules.
Elo rating against SF
Despite important illegal moves, we can try to estimate the strength and rating of gpt-4.
Specifically:
gpt-4scores 7.03% for games with only legal moves (4.5 / 64 games)- if we count all 94 games (being legal of illegal, considering illegal moves lead to a defeat for GPT)
gpt-4scores 4.79% (4.5 / 94).
A first clear observation is that the absolute score is very low.
The Elo rating is then very low, too, and largely inferior to gpt-3.5-turbo-instruct.
- 1371 Elo against SF and only with legal games/moves
- 1305 Elo against SF and with all games
Details below:
Robustness and Elo rating of gpt-4 vs random engine
The objective was to assess ability of gpt-4 to play legal moves, even with a strange and weak opponent.
Out of 85 games against SF, 59 were legal games and 26 were illegal games, hence 31% of illegal games. Illegal moves:
| illegal_move | |
|---|---|
| 12… | 2 |
| 9… | 1 |
| exd2+ | 1 |
| Qae8# | 1 |
| gxh7+ | 1 |
| 17… | 1 |
| Qh5 | 1 |
| exd8 | 1 |
| 14… | 1 |
| gxh8 | 1 |
| Qd4 | 1 |
| Bxa6 | 1 |
| Qh4# | 1 |
| Bxf8 | 1 |
| 5. | 1 |
| cxd8 | 1 |
| Rxg8 | 1 |
| Nxg4 | 1 |
| 16… | 1 |
| 6. | 1 |
| fxg7 | 1 |
| Qd5+ | 1 |
| Qxc8# | 1 |
| Qxd8 | 1 |
| Qd7 | 1 |
A first and main pattern is simply incorrect moves (no 1-0, no 1-, no incorrect promotion, or starting comment).
Another important pattern is the use of number to indicate the move number, but without the move!
The overall conclusion is that random chess engines are disturbing gpt-4 and causing specific difficulties. The illegal moves are not easy to fix.
The performance score of gpt-4 is:
- 99.15% for games with only legal moves (58.5/59 games)
- 68.82% for all games, being legal or illegal (58.5/85 games)
Hence, gpt-4 is almost capable of winning with a perfect score against random chess engine, but there is a condition: it should be able to play legal moves all along, which is not the case.
Robustness of gpt-4 with random first moves
I didn’t gather games with random first moves.
I considered that the results with gpt-4 were already conclusive about its inability to play legal moves.
Conclusion and discussion about ChatGPT-4
The observations that have been reported mainly in the X/Twitter space are confirmed: gpt-4 is not able to play an entire game and generates a lot of illegal moves.
Furthermore, gpt-4 is not able to play at the level of gpt-3.5-turbo-instruct and is much weaker.
It is somehow surprising since gpt-4 is a more recent model, with more parameters (?) or at least with innovations that are supposed to give better results than older models.
There could be several explanations:
gpt-4has been fine-tuned for chat, not for text completion, and it can have an impact on the ability to play legal moves. A countermeasure would be to find the “right” prompt, but it’s not that easy. It was already an engineering effort to makegpt-4play chess games. For instance, I implemented a post-process mechanism that automatically converts promotion (contrary to what I have done withgpt-3.5-turbo-instruct), since otherwise the illegal move/game rate would be much higher. There was also more effort to parse the outcome ofgpt-4that tends to not only propose its own move but a series of moves. I also had to play with max_token. Overall, it’s not clear on how to improve the situation at the prompt engineering level: changing system role could be a solution to explore. Another hypothesis is that the fine-tuning has fundamentally changed the model and degrading its ability to play chess – the only solution would be to re-train the model, or undo what has been done (is it thengpt-3.5-turbo-instruct?).gpt-4has been trained on a different chess-related dataset. We completely ignore what training set has been used for eithergpt-4orgpt-3.5-turbo-instructand what is the relationship between the two- setting a better temperature could enhance the results… the few experiments I’ve done with temperature=0.8 were not conclusive. But I admit I didn’t insist much. Intuitively, I am not seeing a reason why temperature would help here: more creativity when you’re unable to play legal moves? I don’t think so, but I can be wrong.
gpt-3.5-turbo (aka ChatGPT-3.5)
Our last model is gpt-3.5-turbo, a chat model.
The results are very negative, and I will be brief:
- out of 30 games against SF, 2 were legal games and 28 were illegal games, hence 93% of illegal games. An analysis of illegal moves shows that most of them are incorrect moves due to inability to master chess rules.
- For the two games against SF with legal moves, the performance score is 0% (0/2 games). Hence, it makes no sense to compute Elo rating.
- Out of 23 games against random chess engine, only 6 were legal games and 17 were illegal games, hence 74% of illegal games.
- Score against random chess engine is 100.0 % for games with only legal moves (6/6), and 26.09 % for all games, being legal or illegal (6/23). Hence
gpt-3.5-turbohas difficulties to beat one of the weakest chess engine and baseline.
The conclusion is that gpt-3.5-turbo is not able to play an entire game and generates a lot of illegal moves.
Summary of results and tldr;
I have compiled 858 games with various GPT models, chess engines, and settings. The goal was to assess the ability of GPTs to play legal moves and to estimate their Elo rating. I have described the variability space of the experiments and thus the limitations of the study. 100$ was the budget, and it was not possible to cover the whole variability space. However, we have solid results and insights:
gpt-3.5-turbo-instructis by far the best model: though there are avoidable errors, the text completion model is often capable of playing end-to-end legal games, even with black pieces or when the game starts with strange openings or against a random chess engine. Games can be long with dozens of moves (and up to 174 moves!).- Even the best model (
gpt-3.5-turbo-instruct) still makes illegal moves in 16% of the games and 0.3% of the total moves played. While it is true that an external system could correct basic errors (like automated promotion or avoiding completing with1-0), in more open-ended and critical domains it is simply not acceptable. Even in a simple and well controlled domain like chess with stable rules and perhaps immense training sets, illegal moves are still present, suggesting that the system is not fully able to induce the rules. - The estimate is that
gpt-3.5-turbo-instructoperates around 1750 Elo (+/- 50). It is quite consistent with what has been reported in the informal X/Twitter space. 1750 Elo is a good level, but it is far from a master level. Originally, I was thinking that it corresponds to top 30% players for Blitz in lichess. But as nicely pointed out https://twitter.com/pappubahry/status/1714624385947218049, lichess Elo differs from FIDE Elo, i.e., lichess Elo tends to be higher than FIDE Elo, and this difference depends on your own Elo rating. So it is more fair to state that 1750 FIDE Elo is in the top 15% of lichess players (Blitz distributions). Another variability aspect in the interpretation of the experiments and results ;) And to what extent lichess is representative of all chess players in the world is another story! - Modifying the prompt with other PGN headers does not alter performance
gpt-3.5-turbo-instructand ability to play legal moves – there is no magic prompt or PGN headers, but the idea of putting “in-context” PGN headers is a general good approach. - Increasing temperature slightly decreases the performance of
gpt-3.5-turbo-instruct. davinci-003, another completion model, is not able to play an entire game because of illegal moves quickly generated, against basic Stockfish engine or random chess engine. It is not a big surprise and seems on par with what has been reported: a weak baseline.- More surprisingly
ChatGPT-4is much more brittle, with a lot of illegal moves (around 30% of the games) and a low Elo rating (around 1300). The illegal moves are not easy to fix, and seem related to inability to master chess rules. Hence,ChatGPT-4, despite being more recent, is a weaker model thangpt-3.5-turbo-instructfor playing chess. I discussed several possible explanations: prompt, temperature, training set, etc. The fine-tuning for chat seems to be the main reason.ChatGPT-3.5-turbohas been tested, too, but it is not able to play an entire game due to the generation of a lot of illegal moves. - There has been some inquiries about the hypothesis GPT-4 is getting worse over time. On the other hand, OpenAI claims about non-regression of their versions https://twitter.com/npew/status/1679538687854661637. Overall, current evidence is weak and lack of transparency of OpenAI does not help. For instance, this viral paper https://arxiv.org/abs/2307.09009 has too many flaws as demonstrated here: https://www.aisnakeoil.com/p/is-gpt-4-getting-worse-over-time. It has also been suspected that continuously updating/fine-tuning the model on new chat data can cause degradation of performance.
With this study, the results about
ChatGPT-4andgpt-3.5-turbo-instructprovide the first solid evidence that training for chat makes GPT worse on a well-defined problem. That’s a big deal. To quote Simon Willison: “How are we meant to build dependable software on top of a platform that changes in completely undocumented and mysterious ways every few months?” In light of the results of this study, no need to say continual learning will be a big challenge for GPTs in the future!
I hope this blog post will help to debunk some overclaims and to clarify the situation. There are several feelings when looking at the results:
- on the one hand, it is impressive that GPTs are capable of playing chess at 1750 Elo, even if it is not perfect. I know many people not capable of playing chess at this level. Also,
gpt-3.5-turbo-instructshows that end-to-end, long games can be played. It is, I think, quite new and remarkable! - It is mind-blowing to me that a text completion model can play chess at this level, without knowing the rules in the first place.
- On the other hand, lots of illegal moves are still played. I don’t know what the good attitude is when mistakes are generated: Should we fix them? If we fix, is it still assessing GPT? Should we let them as they are? Should we consider the game as lost? Should we ask GPT to play another move?
- The illegal move issue has not been solved and robustness matters in many domains and contexts. Perhaps it is not a big deal in chess. Yet, in general, illegal moves are incredibly significant. They are a kind of hallucination, and reflect serious issues in many real-world applications (e.g., military) that people might envision with GPT technology.
- Skepticism about claims (illegal moves) and insistence on replicability (please read Gary Marcus https://garymarcus.substack.com/!) turned out to be justified.
- GPT-like technologies will certainly not revolutionize the chess game (Stockfish and the incredible, specialized, open effort of the chess community are here to stay). What is the point of further exploring this direction? Personally, I’m considering chess as an interesting benchmark for future AI technologies (including GPTs). It’s interesting to have a look at the progress so far, from GPT-2 to this new
gpt-3.5-turbo-instructmodel. Furthermore, the limitations and potentials of this technology can certainly transfer to other problems and tasks.
I also hope the presented methodology and the modelling of variability of possible experiments will be useful for future work.
Exploring the whole variability space can strengthen the results and conclusions, and I will be interested to hear about other possible experiments to perform in the future.
What is sure is that we, collectively, need to share more data and experiments to have a better understanding of the situation.
I will release data and source code in the following days: https://github.com/acherm/gptchess
PS: I’m taking the liberty of editing this blog post to fix typos, clarify some points, and even expand the content. You can track edits and commits here: https://github.com/acherm/acherm.github.io
Acknowledgements. I would like to thank Paul Calcraft and Gary Marcus for their feedbacks, reviews, and discussions.
(new!) I realized that some of my blog post entries are sometimes cited in academic works, so why not using the following bibtex entry?
@misc{acher2023gptschesseloratinglegalmoves,
author = {Mathieu Acher},
title = {Debunking the Chessboard: Confronting GPTs Against Chess Engines to Estimate Elo Ratings and Assess Legal Move Abilities},
year = {2023},
month = {sep},
howpublished = {\url{https://blog.mathieuacher.com/GPTsChessEloRatingLegalMoves/}},
note = {\url{https://blog.mathieuacher.com/GPTsChessEloRatingLegalMoves/}}
}
ChatGPT LLM generative AI variability programming chess