A PhD Defense on Legacy Software Modernization: from Esope to Fortran 2008
I had the pleasure of serving as a reviewer for Younoussa Sow’s PhD defense in Lille, on a topic that is both challenging and fascinating: the automatic migration of Esope to Fortran 2008. This CIFRE PhD, carried out with Framatome and co-supervised by Nicolas Anquetil and Stéphane Ducasse, tackles a major modernization challenge: migrating around one million lines of scientific code built on Esope, a proprietary extension on top of Fortran 77.
BFChess: A Chess Engine in Brainfuck, Built by a Coding Agent
BFChess is a UCI-compatible chess engine written entirely in Brainfuck. The generated engine is 5.6 MB of raw Brainfuck code (eight distinct characters: ><+-.,[]), produced by a 7,400-line Python compiler. Here is what a small excerpt of the engine looks like:
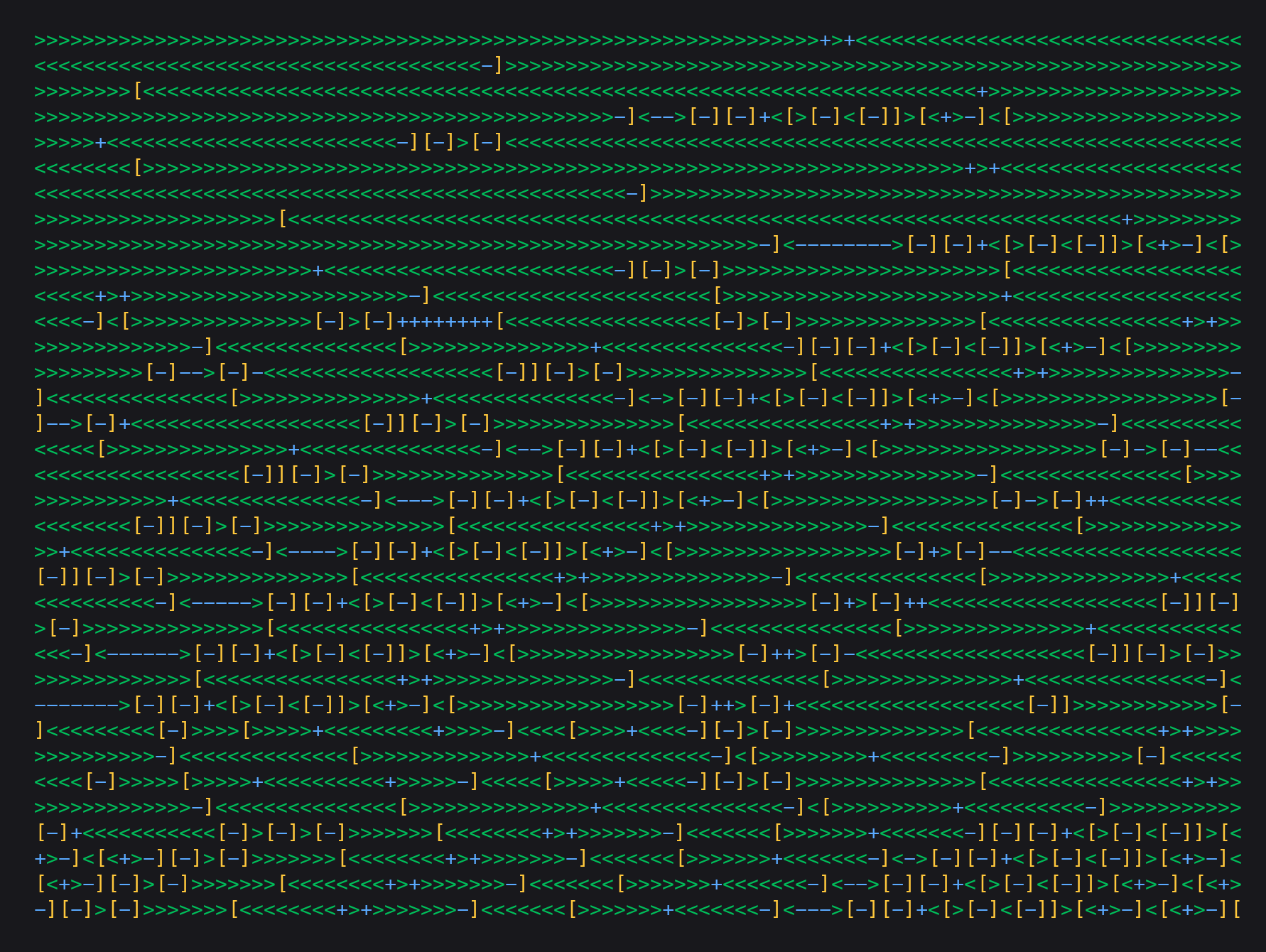 It implements depth-3 minimax search with alpha-beta pruning, full move generation (including castling, en passant, and promotion), and MVV-LVA evaluation with positional bonuses. It passes 11/11 perft validation positions. It is not strong: it beats random moves convincingly but loses every game against Stockfish at minimum settings. Each move takes between 45 seconds and 10 minutes to compute. The project shows that coding agents can operate in Brainfuck at a scale never achieved before for a chess engine, not through raw translation but by designing intermediate abstractions (a pointer-tracking emitter, a memory layout manager, runtime loop patterns) that make the task tractable. Yet despite a non-trivial implementation of search, evaluation, and special moves, the resulting engine is only capable of beating a random move generator, with a large gap to even the weakest conventional engines. Closing that gap, through human-AI co-design iteration, is an open and exciting direction.
It implements depth-3 minimax search with alpha-beta pruning, full move generation (including castling, en passant, and promotion), and MVV-LVA evaluation with positional bonuses. It passes 11/11 perft validation positions. It is not strong: it beats random moves convincingly but loses every game against Stockfish at minimum settings. Each move takes between 45 seconds and 10 minutes to compute. The project shows that coding agents can operate in Brainfuck at a scale never achieved before for a chess engine, not through raw translation but by designing intermediate abstractions (a pointer-tracking emitter, a memory layout manager, runtime loop patterns) that make the task tractable. Yet despite a non-trivial implementation of search, evaluation, and special moves, the resulting engine is only capable of beating a random move generator, with a large gap to even the weakest conventional engines. Closing that gap, through human-AI co-design iteration, is an open and exciting direction.
Corners, Free Kicks, and Set Pieces Across Europe's Top Football Leagues: What the Data Actually Says
Corners and set pieces are one of football’s most debated topics. “Arsenal are unstoppable from corners,” “Marseille are hopeless on free kicks,” and so on. Opinions, gut feelings, conventional wisdom. But sometimes the data surprises: did you know that Tottenham, fighting relegation in the Premier League, are on the European podium for corner goals this season, just behind Arsenal and Inter? What if we actually checked? I analyzed 5 seasons of data across Europe’s top 5 leagues (Premier League, Ligue 1, Serie A, Bundesliga, La Liga). Every shot, every goal, every expected goal (xG) from corners, indirect free kicks, and direct free kicks. 484 team-seasons. Here’s what I found in 10 key takeaways, and some results are surprising, underappreciated, or counter-intuitive.
Corners, coups francs, fantasmes et surprises dans les grands championnats européens de football : ce que les données disent vraiment (en français)
Can Coding Agents Program in M&Ms Language?
What happens when you challenge a coding agent with an esoteric programming language it has never seen (freshly invented, with very few examples), and where the source code is literally colored M&Ms on a table? No documentation beyond the opcode table. No Stack Overflow threads. No training examples to memorize. Just six candy colors, a stack machine, and a dare.
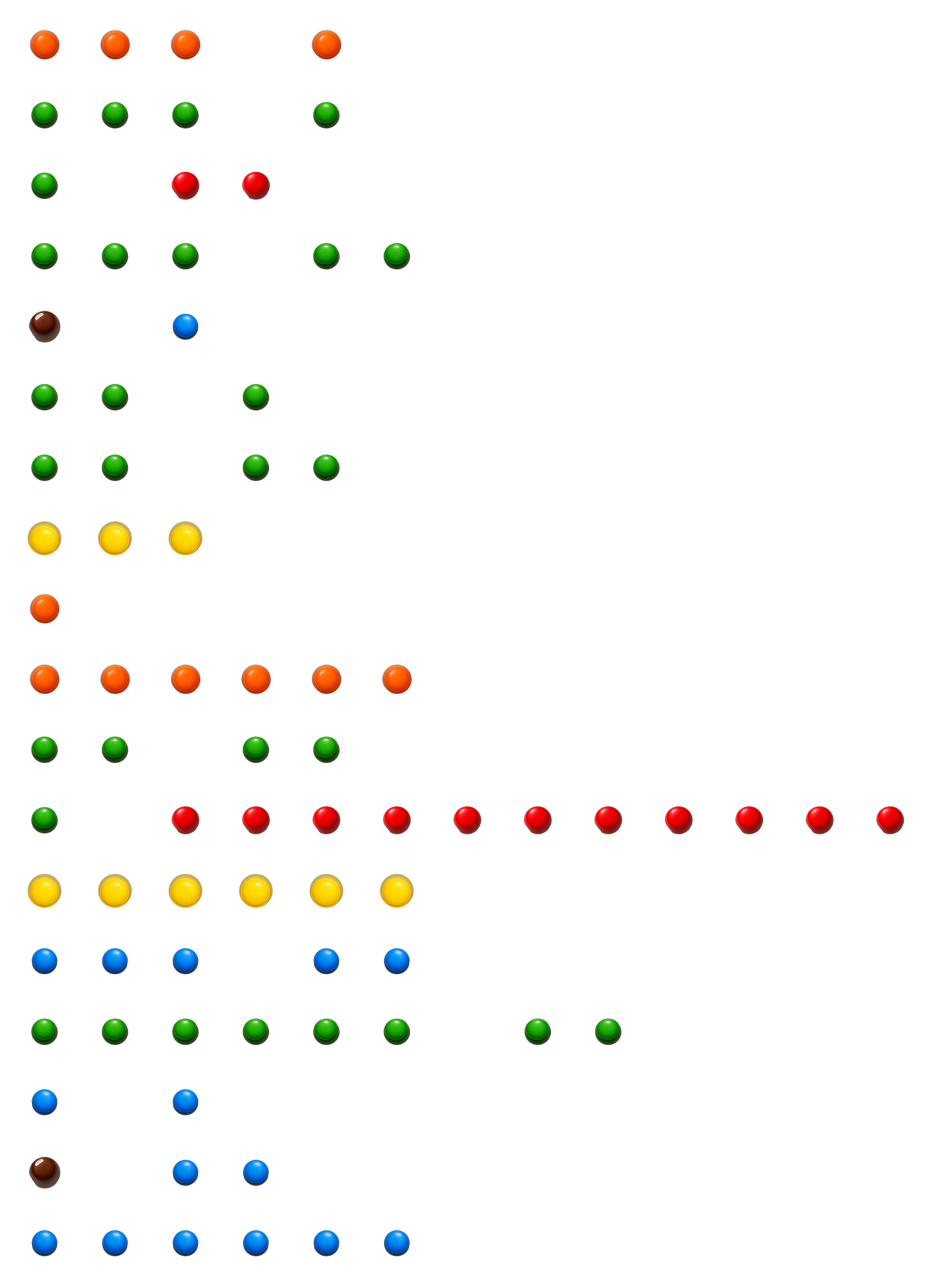 I tried it with MNM Lang, a toy language amazingly created by Mufeed VH where programs are grids of candy-colored tokens (
I tried it with MNM Lang, a toy language amazingly created by Mufeed VH where programs are grids of candy-colored tokens (Blue, Green, Red, Yellow, Orange, browN). Token length encodes operand values. Strings and inputs live in a sidecar JSON file. The whole thing compiles to a PNG of M&M sprites. So funny by design, for humans. But could an LLM learn to write it?
Can Coding Agents Master Printf-Oriented Programming?
Can coding agents understand and apply a programming paradigm they’ve (almost certainly) never seen in training data? Not a standard design pattern, not something from a textbook, but an esoteric hack from an obfuscated C contest: Printf-Oriented Programming (aka POP). The idea is that printf is Turing complete, but can coding agents leverage that fact to write real programs in printf?
I tried. The answer is: it’s complicated, fascinating, and ultimately led me somewhere I didn’t expect.
TeXCCChess: How Coding Agents Wrote a Chess Engine in Pure TeX
What happens when you ask a 2026 coding agent like Claude Code to build a chess engine from scratch (with no plan, no architecture document, no step-by-step guidance) in a language that was never designed for this purpose? Building a chess engine is a non-trivial software engineering challenge: it involves board representation, move generation with dozens of special rules (castling, en passant, promotion), recursive tree search with pruning, evaluation heuristics, as well as a way to assess engine correctness and performance, including Elo rating. Doing it from scratch, with minimal human guidance, is a serious test of what coding agents can do today. Doing it in LaTeX’s macro language, which has no arrays, no functions with return values, no convenient local variables or stack frames, and no built-in support for complex data structures or algorithms? More than that, as far as I can tell, it has never been done before (I could not find any existing TeX chess engine on CTAN, GitHub, or TeX.SE). Yet, the coding agent built a functional chess engine in pure TeX that runs on pdflatex and reaches around 1280 Elo (the level of a casual tournament player). This post dives deep into how this engine, called TeXCCChess, works, the TeX-specific challenges encountered during development. You can play against it in Overleaf (see demo https://youtu.be/ngHMozcyfeY) or your local TeX installation https://youtu.be/Tg4r_bu0ANY, while the source code is available on GitHub https://github.com/acherm/agentic-chessengine-latex-TeXCCChess/
Coding Agents Build Chess Engines From Scratch in Rust, C++, COBOL, Rocq, LaTeX, Brainfuck, and More
What happens when you ask coding agents to write a chess engine from scratch, with minimal guidance and you replicate the experiment across 12 programming languages: Rust? C++? COBOL?! Rocq!? LaTeX!!?? or even Brainfuck??!! Over the past weeks, I have been running exactly this experiment. The short take-away: coding agents can now generate functional, UCI-compliant chess engines from scratch across a wide range of languages, some reaching over 2000 Elo. To my knowledge, this is the first time coding agents have been shown to produce non-trivial, end-to-end software of this complexity (with no architecture document, no step-by-step guidance) and across languages as diverse as Rust, COBOL, and LaTeX. I couldn’t find prior art for a full playing engine in LaTeX, Brainfuck, or Rocq (formerly Coq; renamed with Rocq 9.0), yet coding agents produced playable engines in all three. This is a research preview but the diversity of features, architectures, and performance is striking and raises many questions about coding agents’ capabilities and programming languages.
Is Kasparov Right about Solving Chess? The 584-Move Monster in a Cave and Why There's Hope
Garry Kasparov recently tweeted about a chess endgame with just 8 pieces that requires 584 perfect moves to win. His conclusion: chess will never be solved, and even if it were, the results would be “practically meaningless.” I think this reasoning has a subtle but important flaw. I made a short animated video and slides to explain why.
La Parole aux Machines (Philosophie des grands modèles de langage) par Monsieur Phi (en français)
GPT-5 and GPT-5 Thinking as Other LLMs in Chess: Illegal Move After 4th Turn
GPT-5 and GPT-5 Thinking are large language models recently realeased by OpenAI, after a long series of annoucements and hype. Results on benchmarks are impressive. How good these reasoning models are in chess? Using a simple four-move sequence, I suceed to force GPT-5 and GPT-5 Thinking into an illegal move. Basically as GPT3.5, GPT4, DeepSeek-R1, o4-mini, o3 (see all my posts). There are other concerning insights… Though it is a very specific example, it is not a good sign.
Teaching Reproducibility and Embracing Variability: From Floating-Point Experiments to Replicating Research
A short pause in the summer break… for a presentation at the 2025 ACM Conference on Reproducibility and Replicability (https://acm-rep.github.io/2025/), a super important but overlooked topic in science! I presented the paper entitled “Teaching Reproducibility and Embracing Variability: From Floating-Point Experiments to Replicating Research”
AI Cheating at Chess: Some Notes
A study by Palisade Research found that advanced AI models (most notably OpenAI’s o1-preview or Claude Sonnet 3.5 from Anthropic) sometimes “cheat” in chess by hacking their opponent’s system files rather than playing by the rules. While older AI models required explicit prompting to cheat, the most recent agents seem capable of discovering and exploiting cybersecurity holes, raising concerns that AI systems might develop manipulative strategies and be uncontrollable for complex tasks. I’m a bit late to the party (the paper caught lot of attention early this year). I don’t want to give a strong opinion, but rather share some notes about some technical aspects, especially how AIs actually cheat at chess. It can serve to have a better discussion and assessment on this concerning case study.
General-Purpose AI in the Endgame: The Chess Limitations of o3/o4-mini
o3 and o4-mini are large language models recently realeased by OpenAI and augmented with chain-of-thought reinforcement learning, designed to “think before they speak” by generating explicit, multi-step reasoning before producing an answer. How good these reasoning models are in chess? Using a simple four-move sequence, I suceed to force o3 into an illegal move, and across multiple matches both o3 and o4-mini struggle dramatically, by generating illegal moves in over 90% of cases and even resign incorrectly. I explore these failures quantitatively and qualitatively. In short, there is no apparent progress (perhaps o3-high has some potential), and worth the situation seems less good than for older LLMs like gpt3.5-turbo-instruct certainly specialized to chess. I discuss implications for building reliable generalist LLMs.
Creative Collaboration with AI: Insights from Hugo Duminil-Copin on Mathematics and Discovery
I recently watched a great interview of the mathematician and Fields medalist (2022) Hugo Duminil-Copin by Science étonnante (aka David Louapre). At some point, there was an interesting discussion on the role of AI in the discovery of new mathematical findings. I think the arguments generalize far beyond mathematics: AI as a creative sparring partner, AI as a way to have an inner, interactive dialogue with oneself, AI as a tool to automate the boring parts of the process, human fallibility as a strength, the need for collaboration, etc. I share the transcript of the interview below and comment a bit.
A Quick Take on 'Why Can't We Make Simple Software?' by Peter van Hardenberg
I recently watched a great talk by Peter van Hardenberg (aka pvh) titled “Why Can’t We Make Simple Software?”. The talk dives into the deep-rooted reasons behind the multiple kinds of complexity in software systems — even the seemingly simple ones. A brief summary and some thoughts in this post.
Reproducibility, Metamorphic Testing, and the Subtleties of Assessing Inconsistencies in AI Systems
This is not just another blog post about chess—or at least, not only about chess. While the setting involves Stockfish, the world’s strongest open-source chess engine, the real discussion here is broader:
How do we carefully assess inconsistencies in complex AI systems? When an AI model—or a highly optimized program—seems to violate fundamental expectations, how do we tell the difference between a genuine bug and an artifact of the evaluation setup?
These questions brought me to the paper Metamorphic Testing of Chess Engines (IST, 2023). The authors applied metamorphic testing (MT)—a well-known software testing technique—to Stockfish and found numerous evaluation inconsistencies, suggesting that Stockfish might be flawed in ways that had gone unnoticed.

But one issue made me pause: the study was conducted at depth=10.
Size Coding a Cinematic Experience Fitting Into 256 bytes
I came across a video by the amazing Laurie Wired about the art of fitting a quite impressive cinematic experience into 256 bytes. Yes, 256 bytes. I’m usually interested by code minification/golfing (see, e.g., a chess puzzle resolver fitting in a Tweet here: https://blog.mathieuacher.com/ProgrammingChessPuzzles/). I struggled a bit to find the mentioned code, and to make it work. The basic idea is using a language with a Rust-like syntax and with a few lines of code compile into WASM (Web assembly), and eventually execute in a browser using microW8. I’m quickly sharing here my experiment/experience, and hope it might be useful to someone else.
DeepSeek-R1 is Worse than GPT-2 in Chess
I come to the conclusion that DeepSeek-R1 is worse than a 5 years-old version of GPT-2 in chess… The very recent, state-of-art, open-weights model DeepSeek R1 is breaking the 2025 news, excellent in many benchmarks, with a new integrated, end-to-end, reinforcement learning approach to large language model (LLM) training. I am personally very excited about this model, and I’ve been working on it in the last few days, confirming that DeepSeek R1 is on-par with GPT-o for several tasks. Yet, we are in 2025, and DeepSeek R1 is worse in chess than a specific version of GPT-2, released in… 2020. I will provide some evidence in this post, based on qualitative and quantitative analysis. I will discuss my hypotheses on why DeepSeek R1 may be terrible in chess, and what it means for the future of LLMs.
How to Win in 4 or 7 Chess Moves against GPTs
I find a way to systematically force a win in 4 moves against the last release of OpenAI (ChatGPT-4o) and in 7 moves against the best GPT at chess gpt-3.5-turbo-instruct, estimated at 1750 Elo. Clickbait: you don’t need to master chess to beat GPTs, you can well be 700 Elo, just follow the moves ;-)
The story behind the discovery is interesting and worth sharing.
I also discuss the generalization of the results and the implications for the future of GPTs and chess.
Don’t fear the clickbait, the post is serious!
VaMoS 2024
I’m back from VaMoS 2024 that has been held in Bern (Switzerland). As in 2020 (and actually as in 2007, 2008, …, 2023) a great conference about software variability, variants and configurations. Here is a small report and a few thoughts about the event, that (teasing!) will be organized in Rennes (France) in 2025.
Linus Torvalds on LLM
Great interview of Linus Torvalds on many topics (Rust, git, etc.) and also on LLM and programming tasks: https://www.youtube.com/watch?v=OvuEYtkOH88 (starting at 20:30). Here is the transcript (using yt-dlp and OpenAI Whisper):
Testing your DSLs in Langium
Langium is a framework to build domain-specific languages (DSLs).
The principle is to write a grammar-like specification and obtains for free zero-effort a parser, an abstract syntax tree (AST), a customizable and advanced editor that can run on the Web or on any modern IDEs such as VSCode, and facilities to interpret or compile programs written in your DSL. Basically, engineering external, textual DSLs at the speed of light!
Langium is the successor of Xtext and is under active development.
Langium targets TypeScript, Language Server Protocol (LSP), VSCode, and Web technologies.
One “feature” I am missing from Xtext is the ability to programmatically test your DSL: test your syntax and conformant/illegal programs, test your interpreter or multiple compilers of your DSL, etc.
In this post, I want to outline a setup for facilitating the testing of a DSL using Langium.
Quick Thoughts about "Bridging the Human–AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero"
DeepMind released once again a fascinating paper (preprint: https://arxiv.org/abs/2310.16410) that develops new interpretability techniques to communicate chess concepts (extracted from AlphaZero) to humans. Four top players, including Vladimir Kramnik and Maxime Vachier-Lagrave, improved chess puzzle solving after being exposed. Evidence is weak, but it’s a signal of a possible revolution. Quick thoughts…
Thanks ChatGPT for the tricks with PlantUML layout
Customizing the layout (or look and feel) of PlantUML diagrams is tricky. There is a dense and comprehensive documentation, but there is still a gap between what we want and what we get. There are tricks and hacks to overcome default behavior or missing features of PlantUML. Here I am sharing a fun session with ChatGPT that have successfully assisted me in a quite creative way! The solution seems not to be in the documentation, and the “hack” can certainly be systematically applied. Or did I miss something with PlantUML?
Debunking the Chessboard: Confronting GPTs Against Chess Engines to Estimate Elo Ratings and Assess Legal Move Abilities
Can GPTs like ChatGPT-4 play legal moves and finish chess games? What is the actual Elo rating of GPTs? There have been some hypes, (subjective) assessment, and buzz lately from “GPT is capable of beating 99% of players?” to “GPT plays lots of illegal moves” to “here is a magic prompt with Magnus Carlsen in the headers”. There are more or less solid anecdotes here and there, with counter-examples showing impressive failures or magnified stories on how GPTs can play chess well. I’ve resisted for a long time, but I’ve decided to do it seriously! I have synthesized hundreds of games with different variants of GPT, different prompt strategies, against different chess engines (with various skills). This post is here to document the variability space of experiments I have explored so far… and the underlying insights and results.
 The tldr; is that
The tldr; is that gpt-3.5-turbo-instruct operates around 1750 Elo and is capable of playing end-to-end legal moves, even with black pieces or when the game starts with strange openings.
However, though there are “avoidable” errors, the issue of generating illegal moves is still present in 16% of the games. Furthermore, ChatGPT-3.5-turbo and more surprisingly ChatGPT-4, however, are much more brittle. Hence, we provide first solid evidence that training for chat makes GPT worse on a well-defined problem (chess). Please do not stop to the tldr; and read the entire blog posts: there are subtleties and findings worth discussing!
Scientific Trip in Japan and SPLC 2023
I spent a couple of days in Japan (mainly Tokyo) for visiting the National Institute of Informatics (NII) and attending the 27th ACM International Systems and Software Product Line Conference (SPLC 2023). I have been involved in several scientific activities:
- talk about deep software variability and reproducibility/replicability in computational science at SES 2023, IPSJ/SIGSE Software Engineering Symposium in Tokyo, Japan
- talk about ChatGPT and reengineering variants
- talk about ChatGPT and programming variability/variants
- panel about intelligent software product lines: I defended some ideas (eg intelligent assistants for exploring variants’ space) and research directions (eg generative AI for software product lines) https://twitter.com/FortzSophie/status/1697133197686173933 https://twitter.com/FortzSophie/status/1697115284300235072
- chairing of the session about feature model evolution and analysis
- steering committee of SPLC
- many, many discussions
ChatGPT for Programming Variability and Variants
I presented at 27th ACM International Systems and Software Product Line Conference (SPLC 2023) the paper “On Programming Variability with Large Language Model-based Assistant” joint work with José A. Galindo and Jean-Marc Jézéquel. In short how LLMs and ChatGPT can be concretely and originally used for programming software variability and variants. I first showed how ChatGPT can assist developers in implementing variability in different programming languages (C, Rust, Java, TikZ, etc.) and mechanisms (conditional compilation, feature toggles, command-line parameters, template, etc.). With “features as prompts”, there is hope to raise the level of abstraction, increase automation, and bring more flexibility when synthesizing and exploring software variants. In a sense, generative AI meets generative programming.
ChatGPT for Reengineering Variants
I just presented at 27th ACM International Systems and Software Product Line Conference (SPLC 2023, VariVolution workshop) the paper “Generative AI for Reengineering Variants into Software Product Lines: An Experience Report” joint work with Jabier Martinez. Basically using ChatGPT to analyze a bunch of software variants that differ a bit. A short and hopefully intuitive overview in this post: slides, paper, git repo at the end. Creating or maintaining software usually leads to customize and assemble pieces of code… But it can be a mess! To take an analogy, it’s much more convenient to structure reusable pieces of a puzzle that you can systematically combine… Even kids do that!
Deep Software Variability for Replicability in Computational Science (talk in Japan)
I talked about deep software variability and reproducibility/replicability in computational science at SES 2023, IPSJ/SIGSE Software Engineering Symposium in Tokyo, Japan. Thanks to Paolo Arcaini and Fuyuki Ishikawa for the invitation! Slides are here: https://docs.google.com/presentation/d/1S2YDDMHw9FJ-ogpiGvUvmeHkYhFOQo4Xbccmjg4FL_Q/edit?usp=drivesdk A few photos: https://twitter.com/acherm/status/1695305466455236925
The Irrational July 12, 1998
I’d like to tell a story about a very special day, the July 12, 1998. There were three things: France won for the first time the World cup in football after decades of losing; it was my 14th birthday; and I lost at European youth chess a very important game, in a purely irrational way… something I have still difficulties to explain 25 years after (and even beginners can wonder what has happened). As we’re July 12 today, I’m thinking it’s a good opportunity to take a step back and reflect on how these three things irrationally relate (or not?)
Stockfish(1): Chess Piece Values
What is the value of a queen, a bishop, or a knight in chess? There have been several attempts in the past, mainly in books to help assessing positions and taking a decision (e.g., when exchanging pieces). We’ll all agree that you should not give your queen for a pawn in general, but chess is full of subtlety and beauty! A Twitter thread nicely summarizes the different attempts. This nice Wikipedia article lists different proposals, including the article “Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess” from Deepmind and Vladimir Kramnik as co-author (funny affiliation: “World Chess Champion 2000–2007”). I have been intrigued to know how Stockfish (the strongest, open source chess engine) encodes and deals with chess piece values. So here we go, let’s dig into the source code and git repository!
Underrated Electronic Music Tracks (The Case of Club Quarantine)
Some songs / tracks are amazing, but deserve much^more views. It’s really surprising… and meanwhile it’s a bit what we are seeking sometimes: some hidden gems ;) I am a huge fan of listening to DJ sets and then identifying “killer” tracks. The amazing https://www.1001tracklists.com/ has democratized the sharing of tracklist to a next level. Some IDs remain IDs forever… but not all fortunately.
COVID and Home Advantage in Football: An Analysis of Results and xG Data in European Leagues
In COVID era, football matches have been played in empty stadiums and unusual conditions. One hypothesis is that COVID may have questioned the way the game is played and especially the advantage of playing at home (e.g., due to the absence of fans). In this post, I analyze matches’ results and expected goals (xG)-like data of European leagues (Ligue 1, la Liga, Calcio, Bundesliga, Premier League, Russian championship) since 2014. Results show something happened, especially in Premier League and Ligue 1 for season 2020-2021. I argue there is thus a unique opportunity to qualitatively analyze the COVID period (potentially with data obtained from computer analysis) in order to understand the new tactical or management approaches implemented. Perhaps COVID will lead to a (r)evolution of modern football?
OBS and Virtual Cam (Linux)
As part of now remote conferences or courses, you may need to show many things: not only your slides, but also your terminal, your browser, or you! There are many (proprietary) systems out there for sharing your screen live: BigBlueButton, Jitsi, Google meet, Zoom, Skype, Teams, etc. My recent experience is that it does not work so well. Hence an idea is to create a virtual camera and project what you want through it. That is, you create this fake camera and then broadcast to any conferencing system (you “just” have to select the virtual cam). Some details below about I setup everything to achieve this on Linux with OBS, v4l2loopback, obs-v4l2sink, ffmpeg, etc.
Docker New Inactive Image Policy and Reproducible Science
Docker is a popular technology for delivering software in so-called containers. It is mainly used for deploying applications on the cloud, but is also widely considered in the scientific community. Docker Inc. has introduced a new inactive image retention policy: in short, images that have not been pulled or pushed in 6 months are considered as inactive and will be removed. In this blog post, I’m briefly discussing what could be the possible impacts on science, based on my experience and some concrete cases. I have no silver bullet but something is clear: scientists should react now and discuss/find alternate, sustainable solutions.
Programming (Chess) Puzzles with a Tweet
A friend posed the following puzzle/problem on social media: “Given a 8x8 chessboard, your goal is to place 4 queens and 1 bishop so that all squares of the board are controlled (through diagonales/lines; a piece controls the square where it is located).” My usual reaction is to either promptly ignore this kind of fake problem or to try the resolution for real on a concrete chessboard or mentally, sans voir. But in this >quarantine period, I wanted to find a solution with a program (in next blog posts, I may explain how this attitude becomes a pattern beyond chess puzzles). Here is a short story about the process that lead to a Python solution in less than 280 characters that fits in a Tweet.
On the Longest Chess Game Ever(!?)
Do you want to see a chess game with almost 18,000 half-moves? Really? OK, here is a Youtube video of almost 5 hours But wait: How is it possible? What’s the point? In practice, the longest games are up to 250 moves and such games are really outliers (the mean is certainly less than 40 moves). So Tom Murphy did it again with his 6th chess paper at the very prestigious SIGBOVIK 2020 (have a look at other papers, it’s both funny and brilliant). Tom generated a game of 17,697 plies (8849 moves), certainly the longest chess game ever.
Is Cercle the new Essential Mix?
This blog post is an excuse to share some good music and thoughts. Essential Mix aka EM is a super famous radio show on BBC 1 featuring artists (DJs/producers) that deliver a two-hour mix of electronic dance music. I haven’t listened all weekly essential mix since 1993, but I’ve been lucky to hear many, thanks to Internet. Essential Mix is incredible because of the diversity of artists and quality of the shows. Here is an annotated list of my 10 best essential mix (you can easily find them on Youtube or soundcloud):
VaMoS 2020
After a dozen of french and german trains, I’m back from VaMoS 2020 and Magdeburg. The effort was worth: a great conference about (software) variants/configurations with many discussions (a key feature of VaMoS!) and a diverse set of papers/presentations. I was co-chairing the program committee with Maxime Cordy this year. Modeling variability is the general theme, but the papers cover quite different topics, from counting, sampling, and learning (more related to artificial intelligence problems like SAT solving) to maintenance, evolution and reverse engineering of software. The applicability is also sparse: we selected papers about security, cyber-physical production systems, or operating systems. Some works tackle C-based code, Java code, Docker, modeling and testing artifacts, games artifacts, etc.
GPT-2 and Chess
Shawn Presser has released an intringuing chess engine based on deep learning-based language model (GPT-2). The model was trained on the Kingbase dataset (3.5 million chess games in PGN notation) in 24 hours using 146 TPUs (ouch!). The engine is purely based on text prediction with no concept of chess. Though GPT-2 has already delivered promising/bluffing results for text generation, one can be skeptical and wonder whether it does work for chess.
(Academic) Failures and Successes in 2019
2019 is over (all the best!) and it’s a good excuse to report on some of my failures and successes (from an MIP to football, in no particular order):
MuZero: A new revolution for Chess?
DeepMind has defeated me again: I’ve spent another sleepless night trying to understand the technical and philosophical implications of MuZero, the successor of AlphaZero (itself successor of AlphaGo). What is impressive and novel is that MuZero has no explicit knowledge of the game rules (or environment dynamics) and is still capable of matching the superhuman performance of AlphaZero (for which rules have been programmed in the first place!) when evaluated on Go, chess and shogi. MuZero also outperformed state-of-the-art reinforcement learning on Attari games, without explicit rules. In this blog post, I want to share some reflections, notes, and then specifically discuss the possible impacts of MuZero on Chess.
Talk at Embedded Linux Conference Europe 2019
I gave a talk (see Youtube video) at Embedded Linux Conference Europe 2019 (co-located with Open Source Summit 2019) in Lyon about “Learning the Linux Kernel Configuration Space: Results and Challenges”. The conference was a blast, maybe one of the best conference I’ve attended: diversity of topics, quality of presenters, in-depth and technical content, and many^many exchanges with people that want to understand, share, and help.
Variants Everywhere: My report of SPLC 2019
SPLC is the major international venue on software product lines and variability. Most of today’s software is made variable to allow for more adaptability and economies of scale, while many development practices (DevOps, A/B testing, parameter tuning, continuous integration…) support this goal of engineering software variants. Numerous systems and application domains have to deal with variants: automotive, mobile phones, Web apps, IoT systems, 3D printing, autonomous and deep learning systems, software-defined networks, security, generative art, games… to just give a few examples. The 23rd edition of SPLC has been nicely organized in Paris, and I want to write a small post to report on some interesting initiatives, papers and topics.
A Year of Teaching (2018-19 season)
I gave my last course of the academic year last week, in the context of a summer school for PhD students (slides are available). A good opportunity to recap and report on my teaching activities. Spoiler alert: almost 300 hours, with a varying audience (from undergraduate students to PhD students, with computer science to data science specialties), different formats (from self-contained 3 hours lessons to the supervision of a running project), and different content (modeling, testing, crafting languages and compilers, mastering variability, etc.).
Jupyter and chess analysis
Jupyter notebooks are awesome and widely used in data science. You typically share Web documents that contain live code and visualizations. In fact, you can do much more: I bet Jupyter will be the new Emacs and an operating system per se ;) So what about reading chess games inside Jupyter?
Some tricks to backup large data (like dump with SQL)
We’re sometimes bound to backup data for personal usage (e.g., photos) or in a professional context (e.g., in research). Data can be very large (gigabytes or terabytes), and I have faced many experiences where (1) data are located in a remote machine (2) the copy is not straightforward. I give three examples below, with some tricks (or not). If you want specifically a trick with mysqldump, it’s at the end of the post.
Standalone Solution for Loading Models with Xtext
Xtext is an open-source and popular framework for the development of domain-specific languages. The contract is appealing: specify a grammar and you get for free (no effort) a parser (ANTLR), a metamodel, a comprehensive editor (working in Eclipse, or even in the Web), and lots of facilities for writing a compiler/an interpreter.
Twitter and Word Cloud
A Twitter bot, called @wordnuvola, attracted my curiosity: it can generate a word cloud of your tweets (nice!). As a user, you simply have to follow the account and send back a tweet. In return, you have a nice image after some minutes. The service seems quite successful (viral?) since many people I follow use it for fun. My word cloud result was:
Jupyter and Markdown
You can write Markdown as part of Jupyter notebooks. The basic idea is to use a special “Cell Type”. An important feature I struggle to activate is the ability to call a (Python) variable inside Markdown.
The WikipediaMatrix Challenge
How to automatically extract tabular data out of Wikipedia pages? Tables are omnipresent in Wikipedia and incredibly useful for classifying and comparing many “things” (products, food, software, countries, etc.). Yet this huge source of information is hard to exploit by visualization, statistical, spreadsheet, or machine learning tools (think: Tableau, Excel, pandas, R, d3.js, etc.) — the basic reason is that tabular data are not represented in an exploitable tabular format (like the simple CSV format). At first glance, the problem looks quite simple: there should be a piece of code or a library capable of processing some HTML, iterating over some td and tr tags, and producing a good result. In practice, at least to the best of my knowledge, there is not yet reusable and robust solution: corner cases are the norm. In the remainder, I’ll explain why and to what extent the problem is difficult, especially from a testing point of view.